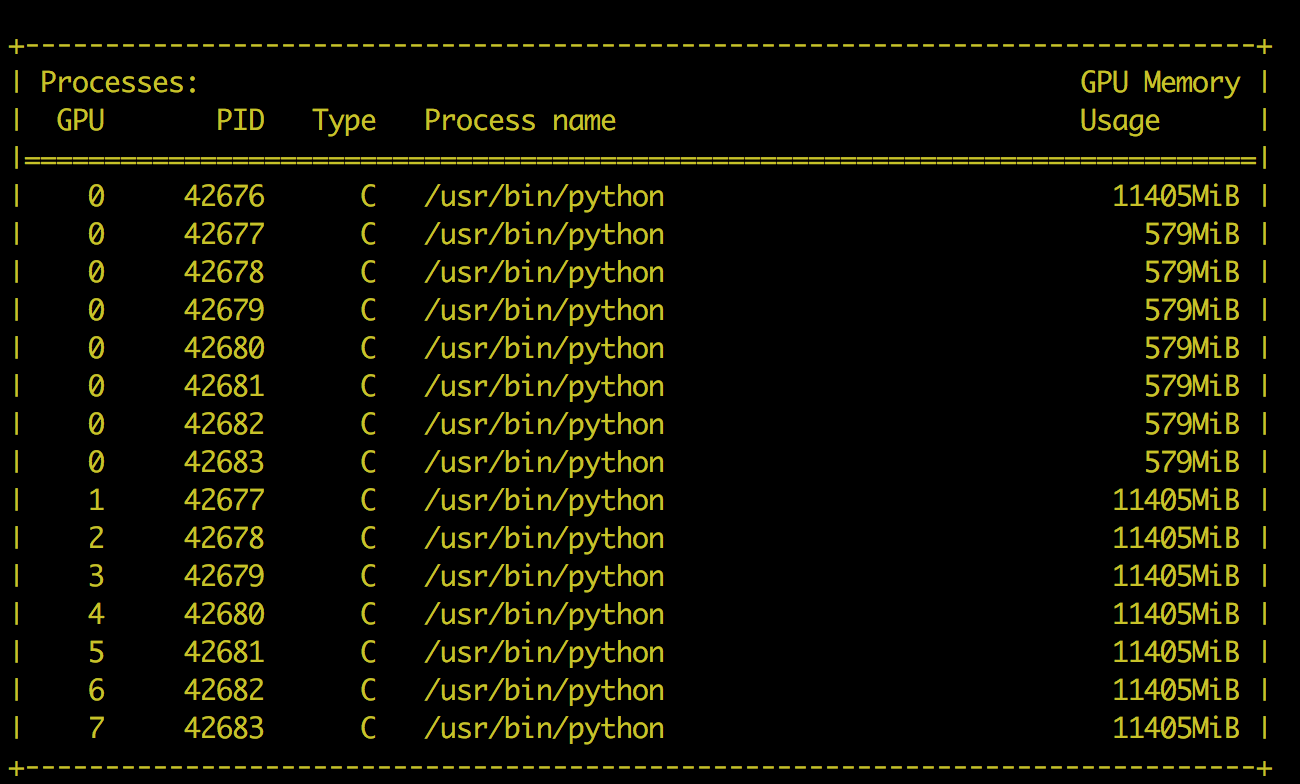
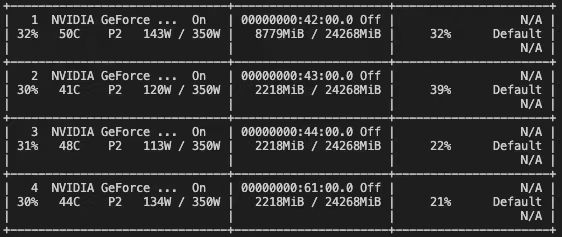
I am training Albert language model using huggingface transformer. While training I notice that on my p3dn instance,gpu 0 is almost completely used but others have around 50% ram unused. I am getting only 85 batch size on this system and above this OOM.
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.33.01 Driver Version: 440.33.01 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:16.0 Off | 0 |
| N/A 77C P0 291W / 300W | 30931MiB / 32510MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla V100-SXM2... On | 00000000:00:17.0 Off | 0 |
| N/A 71C P0 255W / 300W | 18963MiB / 32510MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla V100-SXM2... On | 00000000:00:18.0 Off | 0 |
| N/A 71C P0 95W / 300W | 18963MiB / 32510MiB | 98% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla V100-SXM2... On | 00000000:00:19.0 Off | 0 |
| N/A 68C P0 89W / 300W | 18963MiB / 32510MiB | 72% Default |
+-------------------------------+----------------------+----------------------+
| 4 Tesla V100-SXM2... On | 00000000:00:1A.0 Off | 0 |
| N/A 68C P0 78W / 300W | 18963MiB / 32510MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
| 5 Tesla V100-SXM2... On | 00000000:00:1B.0 Off | 0 |
| N/A 69C P0 96W / 300W | 18963MiB / 32510MiB | 65% Default |
+-------------------------------+----------------------+----------------------+
| 6 Tesla V100-SXM2... On | 00000000:00:1C.0 Off | 0 |
| N/A 69C P0 79W / 300W | 18963MiB / 32510MiB | 95% Default |
+-------------------------------+----------------------+----------------------+
| 7 Tesla V100-SXM2... On | 00000000:00:1D.0 Off | 0 |
| N/A 74C P0 80W / 300W | 18963MiB / 32510MiB | 12% Default |
+-------------------------------+----------------------+----------------------+
I was using default setting for it using data parallel.
I tried distributed training also using python -m torch.distributed.launch --nproc_per_node 8 test_lm.py but It started new job for each and every GPU.
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
Can anyone suggest what I should do for efficient training?
Looks like other processes have might stepped into cuda:0. Have you tried setting CUDA_VISIBLE_DEVICES to make sure that each process only sees one GPU?
The figure you shared looks a little different from the one @karan_purohit attached. Looks like all processes step into cuda:0, which could happen if they use cuda:0 as the default device and then some tensors/context were unintentionally created there. E.g., when you call empty_cache() without a device context, or create some cuda tensor without specifying device affinity.
Can you try setting CUDA_VISIBLE_DEVICES for all processes so that each process exclusively works on one device?
Looks like there is only one process using GPUs in your application while there should be 8 processes? Did you create DDP instances with proper device ids in all processes? Could you please share a min snippet of your Python script that can reproduce this behavior?
How did you set CUDA_VISIBLE_DEVICES? Is it sth like os.environ["CUDA_VISIBLE_DEVICES"]=f"{args.local_rank}" in every individual process before running any cuda related code?
Besides, can you try swapping the order of the following two lines? I am not 100% sure, but ProcessGroupNCCL might create CUDA context on the default device.
Follow your suggestion, I set torch.cuda.set_device to the rank , and it’s work well.
But I still don’t understand the reason behind it, because I used model.to(rank) and input.to(rank), Therefore, shouldn’t each variable be on its own gpu card?
Yes, each of these objects will be moved to the corresponding rank and I assume you are creating CUDA contexts on all devices somewhere else.
Using set_device is an easy method to avoid it as the “offending call” wouldn’t be able to initialize a context on any other device.
Please tell me how CUDA_VISIBLE_DEVICES can solve Tyan’s problem. I encountered the same problem. Why do I need to configure CUDA_VISIBLE_DEVICES? Can you help me?