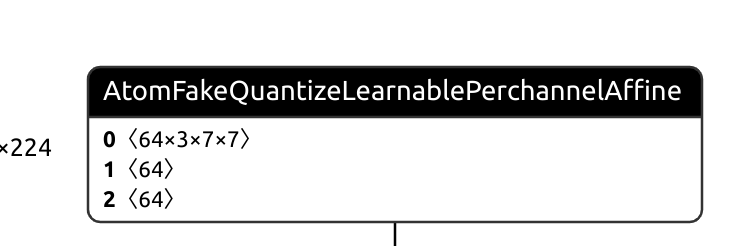
I have a customized op like this:
class AtomFakeQuantizeLearnablePertensorAffine(torch.autograd.Function):
@staticmethod
def forward(ctx, x, scale, zero_point, quant_min, quant_max, grad_factor):
return torch._fake_quantize_learnable_per_tensor_affine(
x, scale, zero_point, quant_min, quant_max, grad_factor
)
@staticmethod
def symbolic(g, x, scale, zero_point, quant_min, quant_max, grad_factor):
logger.debug("symbolic for: AtomFakeQuantizeLearnablePertensorAffine")
return g.op(
"::AtomFakeQuantizeLearnablePertensorAffine",
x,
scale,
zero_point,
quant_min_i=quant_min,
quant_max_i=quant_max,
)
this defined inputs to be 5, but the exported onnx model make quant_min and quant_max as attributes.
this is unexpected, how to avoid it?