Hi everyone,
I created a dynamic actor-critic module deriving from nn.Module. The module is made up of 3 submodules: a shared network made up of a number of convolutional layers and 2 independent parts made up of fc layers that receive the flattened output of the previous module as input. The code that I used is the following:
class Conv3DModelFree(nn.Module):
def __init__(self, in_shape, num_actions, **kwargs):
fc_layers = kwargs["fc_layers"]
super(Conv3DModelFree, self).__init__(
num_actions, features_out=fc_layers[-1])
# super().__init__()
conv_layers = kwargs["conv_layers"]
self.shared_layers = []
self.num_actions = num_actions
self.in_shape = in_shape
self.num_channels = in_shape[0]
self.num_frames = kwargs["num_frames"]
next_inp = None
# =============================================================================
# FEATURE EXTRACTOR SUBMODULE
# =============================================================================
for i, cnn in enumerate(conv_layers):
if i == 0:
self.shared_layers.append(nn.Conv3d(
self.num_channels, cnn[0], kernel_size=cnn[1], stride=cnn[2]))
self.shared_layers.append(nn.LeakyReLU())
else:
self.shared_layers.append(nn.Conv3d(
next_inp, cnn[0], kernel_size=cnn[1], stride=cnn[2]))
self.shared_layers.append(nn.LeakyReLU())
next_inp = cnn[0]
for i, layer in enumerate(self.shared_layers):
if i == 0:
fake_inp = torch.zeros(
[1, self.num_channels, self.num_frames, *self.in_shape[1:]])
fake_inp = self.shared_layers[i](fake_inp)
else:
fake_inp = self.shared_layers[i](fake_inp)
next_inp = fake_inp.view(1, -1).size(1)
# =============================================================================
# ACTOR AND CRITIC SUBMOODULES
# =============================================================================
self.actor_subnet = []
self.critic_subnet = []
for i, fc in enumerate(fc_layers):
if i == 0:
self.shared_layers.append(nn.Linear(next_inp, fc))
self.shared_layers.append(nn.LeakyReLU())
else:
# Separate submodules for the actor and the critic
self.actor_subnet.append(nn.Linear(next_inp, fc))
self.critic_subnet.append(nn.Linear(next_inp, fc))
self.actor_subnet.append(nn.LeakyReLU())
self.critic_subnet.append(nn.LeakyReLU())
next_inp = fc
def forward(self, input)
for i, layer in enumerate(self.shared_layers[:-2]):
if i == 0:
x = self.shared_layers[i](input)
else:
x = self.shared_layers[i](x)
# last 2 shared layers requires a reshape of the input
x = x.view(x.shape[0], -1)
x = self.shared_layers[-2](x)
x = self.shared_layers[-1](x)
action_logits = None
for i, layer in enumerate(self.actor_subnet):
if i == 0:
action_logits = self.actor_subnet[i](x)
else:
action_logits = self.actor_subnet[i](action_logits)
action_logits = self.actor(action_logits)
value = None
for i, layer in enumerate(self.critic_subnet):
if i == 0:
value = self.critic_subnet[i](x)
else:
value = self.critic_subnet[i](value)
value = self.critic(value)
return action_logits, value
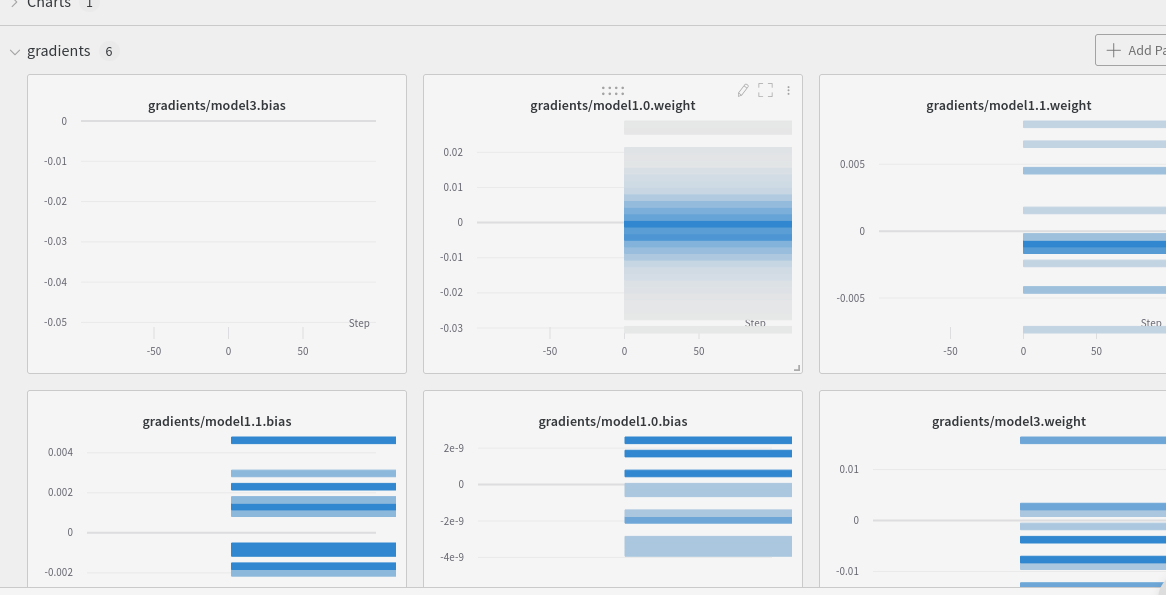
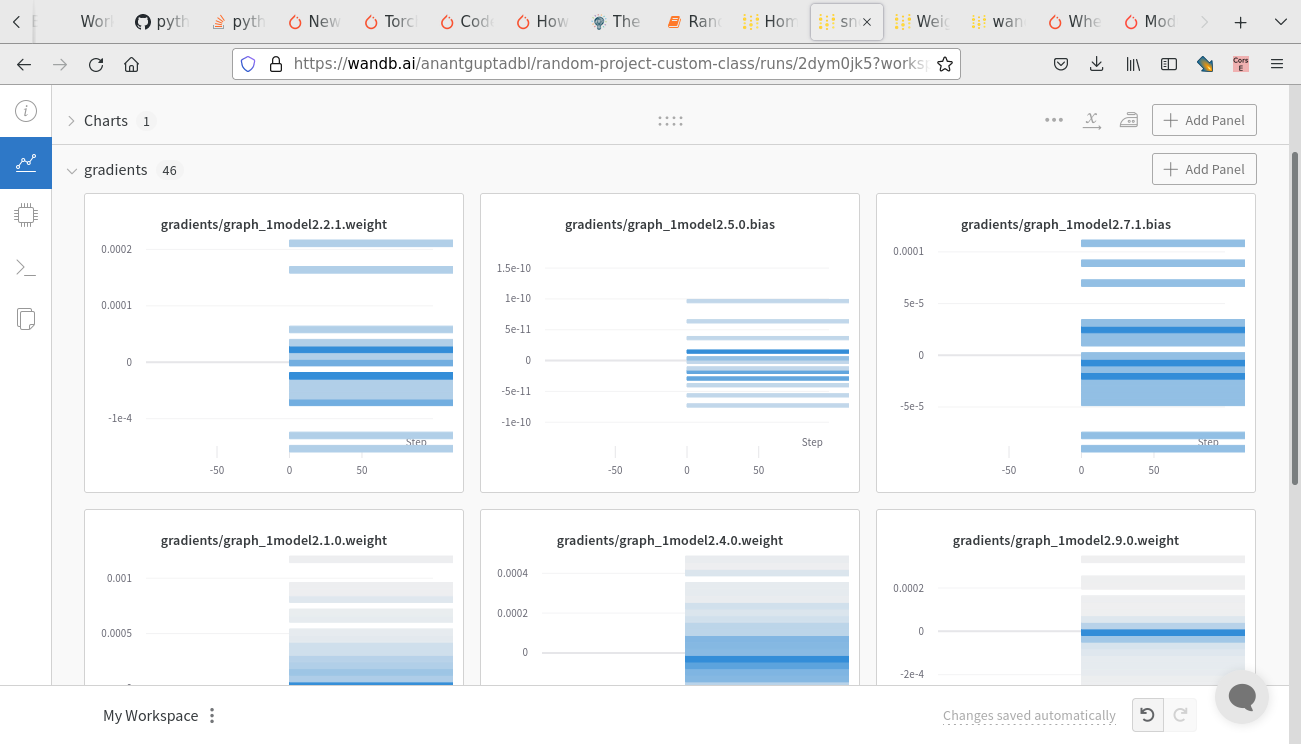
When I use wandb.watch on this class, the graphs do not appear to me probably because wandb cannot identifies the submodules of the network that are included in a list. I tested a different solution, trying to wrap the various pieces in some nn.Sequential modules as follows:
class Conv3DModelFree(OnPolicy):
def __init__(self, in_shape, num_actions, **kwargs):
fc_layers = kwargs["fc_layers"]
super(Conv3DModelFree, self).__init__(
num_actions, features_out=fc_layers[-1])
# super().__init__()
conv_layers = kwargs["conv_layers"]
shared_layers = OrderedDict()
self.num_actions = num_actions
self.in_shape = in_shape
self.num_channels = in_shape[0]
self.num_frames = kwargs["num_frames"]
next_inp = None
# =============================================================================
# FEATURE EXTRACTOR SUBMODULE
# =============================================================================
for i, cnn in enumerate(conv_layers):
if i == 0:
shared_layers["conv_0"] = nn.Conv3d(
self.num_channels, cnn[0], kernel_size=cnn[1], stride=cnn[2])
shared_layers["activ_0"] = nn.LeakyReLU()
else:
shared_layers["conv_"+str(i)] = nn.Conv3d(
next_inp, cnn[0], kernel_size=cnn[1], stride=cnn[2])
shared_layers["activ_" + str(i)] = nn.LeakyReLU()
next_inp = cnn[0]
# flatten the output starting from dim=1 by default
shared_layers["flatten"] = nn.Flatten()
for i, layer in enumerate(shared_layers):
if i == 0:
fake_inp = torch.zeros(
[1, self.num_channels, self.num_frames, *self.in_shape[1:]])
fake_inp = shared_layers[layer](fake_inp)
else:
fake_inp = shared_layers[layer](fake_inp)
next_inp = fake_inp.view(1, -1).size(1)
# =============================================================================
# ACTOR AND CRITIC SUBMODULES
# =============================================================================
actor_subnet = OrderedDict()
critic_subnet = OrderedDict()
for i, fc in enumerate(fc_layers):
if i == 0:
shared_layers["fc_0"] = nn.Linear(next_inp, fc)
shared_layers["fc_activ"] = nn.LeakyReLU()
else:
# Separate submodules for the actor and the critic
actor_subnet["actor_fc_"+str(i)] = nn.Linear(next_inp, fc)
critic_subnet["critic_fc_" +
str(i)] = nn.Linear(next_inp, fc)
actor_subnet["actor_activ_"+str(i)] = nn.LeakyReLU()
critic_subnet["critic_activ_"+str(i)] = nn.LeakyReLU()
next_inp = fc
actor_subnet["actor_out"] = nn.Linear(next_inp, self.num_actions)
critic_subnet["critic_out"] = nn.Linear(next_inp, 1)
self.shared_network = nn.Sequential(shared_layers)
self.actor = nn.Sequential(actor_subnet)
self.critic = nn.Sequential(critic_subnet)
def forward(self, input):
shared_net_output = self.shared_network(input)
action_logits = self.actor(shared_net_output)
value = self.critic(shared_net_output)
return action_logits, value
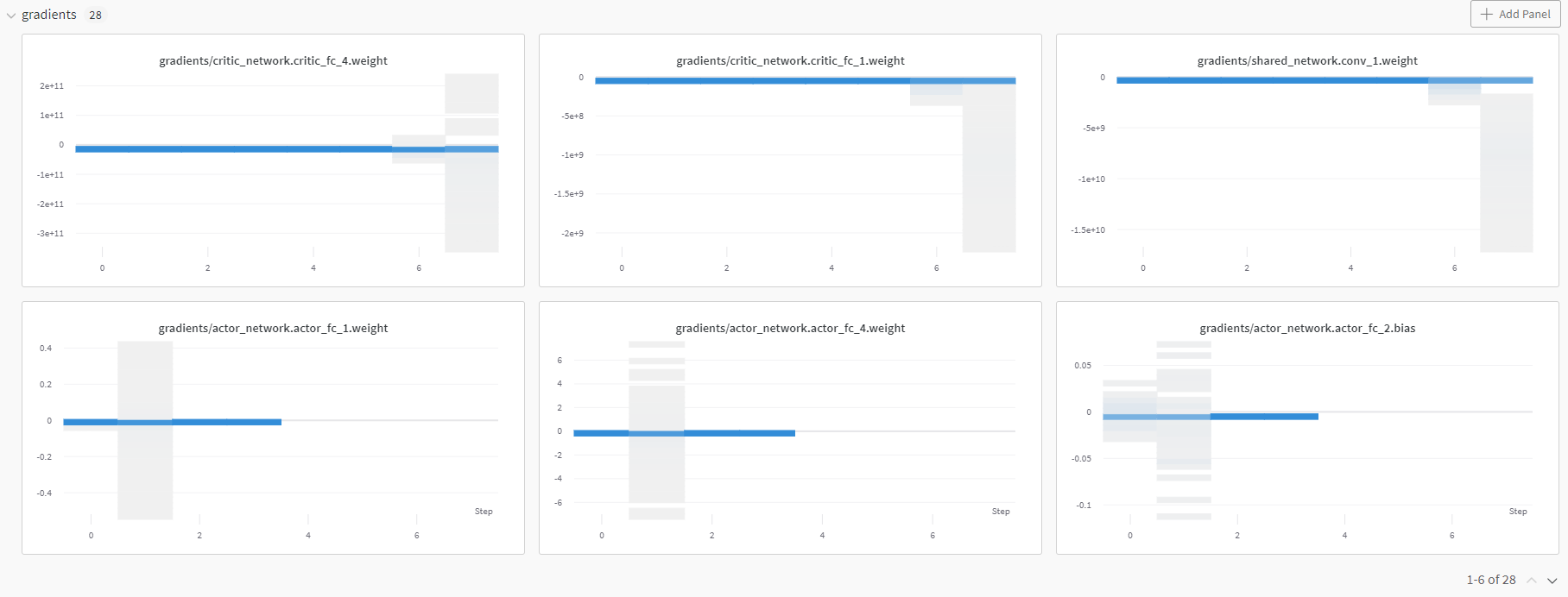
Using this different implementation, I can visualize the graphs but I get completely different results and extremely high loss values. Does anyone know a correct way to define this architecture so that it is viewable on wandb?