Dear pytorch gurus,
I’m building a neural paraphrasing model and
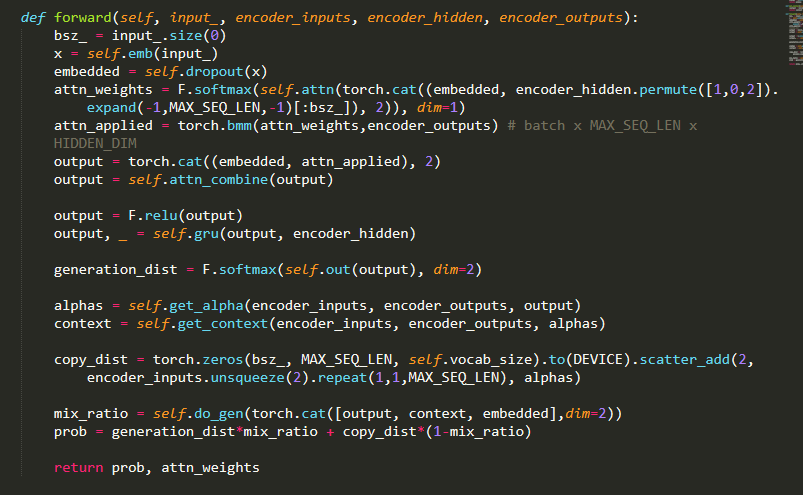
trying to implement copy mechanism, which uses some tokens in the input sequence as they are when producing output tokens.
Easily put, copy mechanism produces a probability distribution over input tokens. After getting the probability, I try to add this to the probability distribution generated by GRU decoder. In the process, I need to scatter copy distribution into a vector of vocab size, where I used torch.scatter_add.
After that I compute mixture of two probability distribution and compute the loss afterward. The problem is, that loss doesn’t decrease after a few epochs. I doubt the gradient doesn’t flow over this operation. Can anyone suggest an alternative process for this implementation?
Thanks deeply in advance.