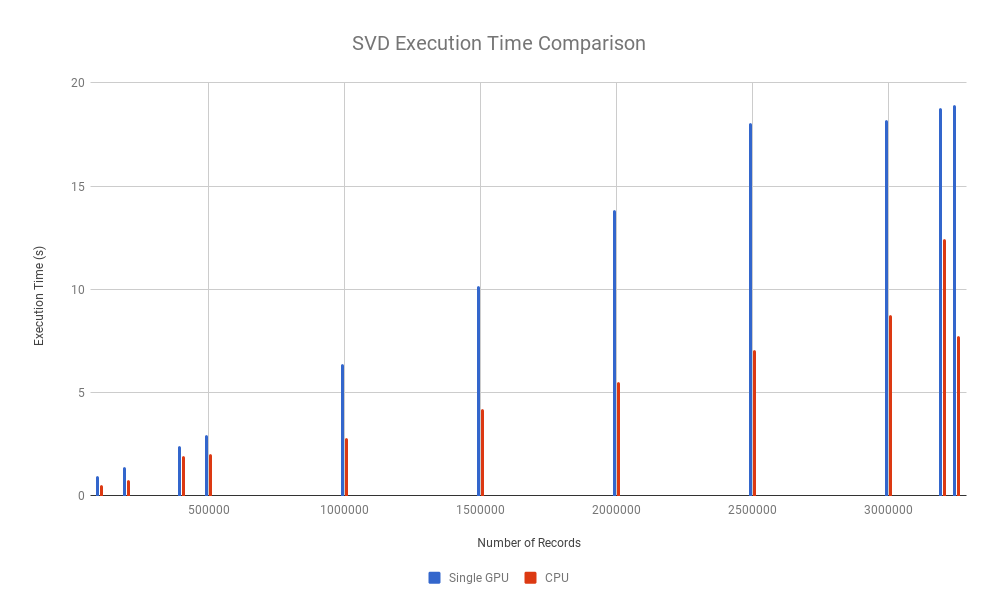
In the following graph, you can see the execution time in seconds taken for Torch.svd in both CPU and GPU. As you can see the time taken for GPU is larger than that time taken for CPU and keeps increasing as we increase the number of records. Please note that the GPU memory has a size of 12 GB and the maximum number of records that can be run with svd is 3.25 million.
import torch
from datetime import datetime
import sys
n_records = sys.argv[1];
x = torch.zeros(n_records, 300).cuda()
s = datetime.now()
u, _, _ = torch.svd(x, some=True)
e = datetime.now()
del x
el = (e-s).total_seconds()
print(el)
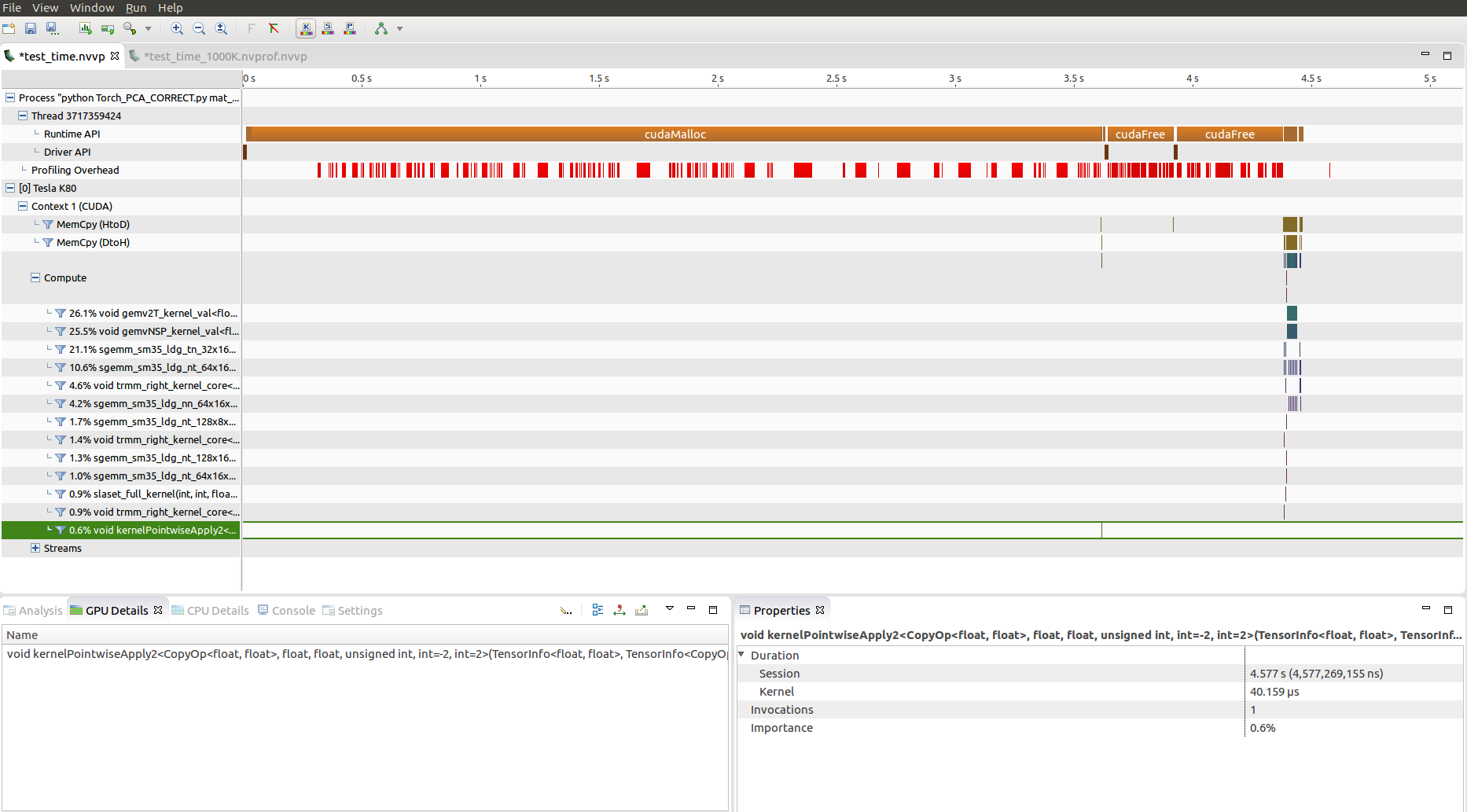
Following is the output from NVIDIA visual profiler for 1000 and 1 million records respectively. As you can see after the ‘kernelPointWiseApply2’ cuda kernel invocation there is a certain amount of idle time that is introduced. This idle time between the first and second kernel functions in the “compute” section has also increased.
This is because magma’s implementation of ?gesvd is used under the hood. Unfortunately, the implementation is not purely on GPU and still calls LAPACK/BLAS functions (https://github.com/maxhutch/magma/blob/master/src/dgesvd.cpp). That is probably why you are seeing these idle times on GPU.
And yes from what I see in the file you pointed out this is not a pure GPU implementation, there are several calls to LAPACK. Thanks very much for the clarification.
Hi, do you solve the problem of GPU is slower than CPU. I encounter the same issue when using the function torch.gesv. Waiting for your apply, thank you!