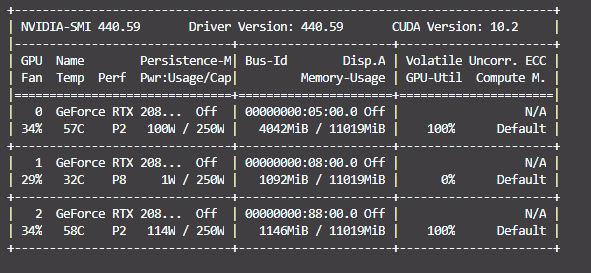
I followed https://github.com/pytorch/vision/blob/master/torchvision/datasets/folder.py to create my own ImageFolder (I called it ImageFolderSuperpixel, folder_sp.py). It works FINE in a single GPU but it meets bugs in a single node, multiple GPUs. Anyone can tell me what is going on here?
Traceback (most recent call last):
File “”, line 1, in
Traceback (most recent call last):
File “/usr/lib64/python3.6/multiprocessing/spawn.py”, line 105, in spawn_main
exitcode = _main(fd)
File “/usr/lib64/python3.6/multiprocessing/spawn.py”, line 115, in _main
self = reduction.pickle.load(from_parent)
_pickle.UnpicklingError: pickle data was truncated
File “”, line 1, in
File “/usr/lib64/python3.6/multiprocessing/spawn.py”, line 105, in spawn_main
exitcode = _main(fd)
File “/usr/lib64/python3.6/multiprocessing/spawn.py”, line 115, in _main
self = reduction.pickle.load(from_parent)
_pickle.UnpicklingError: pickle data was truncated
Traceback (most recent call last):
File “”, line 1, in
File “/usr/lib64/python3.6/multiprocessing/spawn.py”, line 105, in spawn_main
exitcode = _main(fd)
File “/usr/lib64/python3.6/multiprocessing/spawn.py”, line 115, in _main
self = reduction.pickle.load(from_parent)
_pickle.UnpicklingError: pickle data was truncated
Traceback (most recent call last):
File “main.py”, line 102, in
main()
File “main.py”, line 45, in main
classification.start(dataset_path, checkpoints_path, args, **CONFIG[args.dataset])
File “/nfs/hpc/share/coe_hanweiku/xxxnet-pytorch/utils/classification.py”, line 304, in start
mp.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, args))
File “/nfs/hpc/share/coe_hanweiku/xxxnet-pytorch/venv2/lib64/python3.6/site-packages/torch/multiprocessing/spawn.py”, line 200, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method=‘spawn’)
File “/nfs/hpc/share/coe_hanweiku/xxxnet-pytorch/venv2/lib64/python3.6/site-packages/torch/multiprocessing/spawn.py”, line 158, in start_processes
while not context.join():
File “/nfs/hpc/share/coe_hanweiku/xxxnet-pytorch/venv2/lib64/python3.6/site-packages/torch/multiprocessing/spawn.py”, line 108, in join
(error_index, name)
Exception: process 1 terminated with signal SIGKILL
"""Custom Image Datasets API
Image datasets API have two input image directories, which could provide the
interface for superpixel research
Author: Weikun Han <weikunhan@gmail.com>
Reference:
- https://github.com/pytorch/vision/blob/master/torchvision/datasets/vision.py
- https://github.com/pytorch/vision/blob/master/torchvision/datasets/folder.py
"""
import os
import random
import torch
import torch.utils.data as data
from PIL import Image
class VisionDataset(data.Dataset):
_repr_indent = 4
def __init__(self, root, root_sp, transforms=None, transform=None, target_transform=None):
if isinstance(root, torch._six.string_classes):
root = os.path.expanduser(root)
if isinstance(root_sp, torch._six.string_classes):
root_sp= os.path.expanduser(root_sp)
self.root = root
self.root_sp = root_sp
has_transforms = transforms is not None
has_separate_transform = transform is not None or target_transform is not None
if has_transforms and has_separate_transform:
raise ValueError("Only transforms or transform/target_transform can "
"be passed as argument")
# for backwards-compatibility
self.transform = transform
self.target_transform = target_transform
if has_separate_transform:
transforms = StandardTransform(transform, target_transform)
self.transforms = transforms
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
def __repr__(self):
head = "Dataset " + self.__class__.__name__
body = ["Number of datapoints: {}".format(self.__len__())]
if self.root is not None:
body.append("Root location: {}".format(self.root))
if self.root_sp is not None:
body.append("Root superpixel location: {}".format(self.root_sp))
body += self.extra_repr().splitlines()
if hasattr(self, "transforms") and self.transforms is not None:
body += [repr(self.transforms)]
lines = [head] + [" " * self._repr_indent + line for line in body]
return '\n'.join(lines)
def _format_transform_repr(self, transform, head):
lines = transform.__repr__().splitlines()
return (["{}{}".format(head, lines[0])] +
["{}{}".format(" " * len(head), line) for line in lines[1:]])
def extra_repr(self):
return ""
class StandardTransform(object):
def __init__(self, transform=None, target_transform=None):
self.transform = transform
self.target_transform = target_transform
def __call__(self, input, target):
if self.transform is not None:
input = self.transform(input)
if self.target_transform is not None:
target = self.target_transform(target)
return input, target
def _format_transform_repr(self, transform, head):
lines = transform.__repr__().splitlines()
return (["{}{}".format(head, lines[0])] +
["{}{}".format(" " * len(head), line) for line in lines[1:]])
def __repr__(self):
body = [self.__class__.__name__]
if self.transform is not None:
body += self._format_transform_repr(self.transform,
"Transform: ")
if self.target_transform is not None:
body += self._format_transform_repr(self.target_transform,
"Target transform: ")
return '\n'.join(body)
def has_file_allowed_extension(filename, extensions):
"""Checks if a file is an allowed extension.
Args:
filename (string): path to a file
extensions (tuple of strings): extensions to consider (lowercase)
Returns:
bool: True if the filename ends with one of given extensions
"""
return filename.lower().endswith(extensions)
def is_image_file(filename):
"""Checks if a file is an allowed image extension.
Args:
filename (string): path to a file
Returns:
bool: True if the filename ends with a known image extension
"""
return has_file_allowed_extension(filename, IMG_EXTENSIONS)
def make_dataset(directory, class_to_idx, extensions=None, is_valid_file=None):
instances = []
directory = os.path.expanduser(directory)
both_none = extensions is None and is_valid_file is None
both_something = extensions is not None and is_valid_file is not None
if both_none or both_something:
raise ValueError("Both extensions and is_valid_file cannot be None or not None at the same time")
if extensions is not None:
def is_valid_file(x):
return has_file_allowed_extension(x, extensions)
for target_class in sorted(class_to_idx.keys()):
class_index = class_to_idx[target_class]
target_dir = os.path.join(directory, target_class)
if not os.path.isdir(target_dir):
continue
for root, _, fnames in sorted(os.walk(target_dir, followlinks=True)):
for fname in sorted(fnames):
path = os.path.join(root, fname)
if is_valid_file(path):
item = path, class_index
instances.append(item)
return instances
class DatasetFolder(VisionDataset):
"""A generic data loader where the samples are arranged in this way: ::
root/class_x/xxx.ext
root/class_x/xxy.ext
root/class_x/xxz.ext
root/class_y/123.ext
root/class_y/nsdf3.ext
root/class_y/asd932_.ext
Args:
root (string): Root directory path.
root_sp (string): Root directory path for superpixel.
loader (callable): A function to load a sample given its path.
extensions (tuple[string]): A list of allowed extensions.
both extensions and is_valid_file should not be passed.
transform (callable, optional): A function/transform that takes in
a sample and returns a transformed version.
E.g, ``transforms.RandomCrop`` for images.
target_transform (callable, optional): A function/transform that takes
in the target and transforms it.
is_valid_file (callable, optional): A function that takes path of a file
and check if the file is a valid file (used to check of corrupt files)
both extensions and is_valid_file should not be passed.
Attributes:
classes (list): List of the class names sorted alphabetically.
class_to_idx (dict): Dict with items (class_name, class_index).
samples (list): List of (sample path, class_index) tuples
targets (list): The class_index value for each image in the dataset
"""
def __init__(self, root, root_sp, loader, extensions=None, transform=None,
target_transform=None, is_valid_file=None):
super(DatasetFolder, self).__init__(root, root_sp, transform=transform,
target_transform=target_transform)
classes, class_to_idx = self._find_classes(self.root)
classes_sp, class_to_idx_sp = self._find_classes(self.root_sp)
samples = make_dataset(self.root, class_to_idx, extensions, is_valid_file)
samples_sp = make_dataset(self.root_sp, class_to_idx_sp, extensions, is_valid_file)
if len(samples) == 0:
msg = "Found 0 files in subfolders of: {}\n".format(self.root)
if extensions is not None:
msg += "Supported extensions are: {}".format(",".join(extensions))
raise RuntimeError(msg)
if len(samples_sp) == 0:
msg = "Found 0 files in subfolders of: {}\n".format(self.root_sp)
if extensions is not None:
msg += "Supported extensions are: {}".format(",".join(extensions))
raise RuntimeError(msg)
if len(samples) != len(samples_sp):
msg = "Image files is not equal to superpixel files.\n"
if extensions is not None:
msg += "Supported extensions are: {}".format(",".join(extensions))
raise RuntimeError(msg)
self.loader = loader
self.extensions = extensions
self.classes = classes
self.classes_sp = classes_sp
self.class_to_idx = class_to_idx
self.class_to_idx_sp = class_to_idx_sp
self.samples = samples
self.samples_sp = samples_sp
self.targets = [s[1] for s in samples]
self.targets_sp = [s[1] for s in samples_sp]
def _find_classes(self, dir):
"""
Finds the class folders in a dataset.
Args:
dir (string): Root directory path.
Returns:
tuple: (classes, class_to_idx) where classes are relative to (dir), and class_to_idx is a dictionary.
Ensures:
No class is a subdirectory of another.
"""
classes = [d.name for d in os.scandir(dir) if d.is_dir()]
classes.sort()
class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}
return classes, class_to_idx
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (sample, target) where target is class_index of the target class.
"""
path, target = self.samples[index]
path_sp, target_sp = self.samples_sp[index]
sample = self.loader(path).convert('RGB')
sample_sp = self.loader(path_sp)
if self.transform is not None:
torch.manual_seed(1234)
random.seed(1234)
sample = self.transform(sample)
torch.manual_seed(1234)
random.seed(1234)
sample_sp = self.transform(sample_sp)
if self.target_transform is not None:
torch.manual_seed(4321)
random.seed(4321)
target = self.target_transform(target)
torch.manual_seed(4321)
random.seed(4321)
target_sp = self.target_transform(target_sp)
return sample, target, sample_sp, target_sp
def __len__(self):
return len(self.samples)
IMG_EXTENSIONS = ('.jpg', '.jpeg', '.png', '.ppm', '.bmp', '.pgm', '.tif', '.tiff', '.webp')
def pil_loader(path):
img = Image.open(path)
return img
def accimage_loader(path):
import accimage
try:
return accimage.Image(path)
except IOError:
# Potentially a decoding problem, fall back to PIL.Image
return pil_loader(path)
def default_loader(path):
from torchvision import get_image_backend
if get_image_backend() == 'accimage':
return accimage_loader(path)
else:
return pil_loader(path)
class ImageFolderSuperpixel(DatasetFolder):
"""A generic data loader where the images are arranged in this way: ::
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/asd932_.png
Args:
root (string): Root directory path.
root_sp (string): Root directory path for superpixel.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
loader (callable, optional): A function to load an image given its path.
is_valid_file (callable, optional): A function that takes path of an Image file
and check if the file is a valid file (used to check of corrupt files)
Attributes:
classes (list): List of the class names sorted alphabetically.
class_to_idx (dict): Dict with items (class_name, class_index).
imgs (list): List of (image path, class_index) tuples
"""
def __init__(self, root, root_sp, transform=None, target_transform=None,
loader=default_loader, is_valid_file=None):
super(ImageFolderSuperpixel, self).__init__(root, root_sp, loader, IMG_EXTENSIONS if is_valid_file is None else None,
transform=transform,
target_transform=target_transform,
is_valid_file=is_valid_file)
self.imgs = self.samples
self.imgs_sp = self.samples_sp