TorchJD
Hi everyone! I’d like to quickly present my biggest project so far, in collaboration with @Pierre_Quinton: TorchJD. When you train a model with multiple losses, TorchJD allows you to compute the Jacobian of the vector of losses as easily as you would compute the gradient of the scalar loss with autograd. TorchJD also allows you to aggregate these Jacobians such that no loss increases when updating the model parameters (at least given a sufficiently small learning rate). We call this whole algorithm Jacobian descent (JD), hence the name TorchJD.
Computing Jacobians
torchjd.autojac can be used very similarly as torch.autograd, but to compute Jacobians instead of gradients. Here are a few examples comparing autograd and autojac:
torch.autograd.grad: compute gradients:loss = ... # scalar tensor gradients = autograd.grad(loss, model.parameters()) # tuple with 1 gradient per param, that has shape `param.shape`torchjd.autojac.jac: compute jacobians:losses = ... # tensor of shape [m] jacobians = autojac.jac(losses, model.parameters()) # tuple with 1 jacobian per param, that has shape `[m] + param.shape`torch.autograd.backward: compute gradients and accumulate them in the.gradfield of the inputs:loss = ... # scalar tensor autograd.backward(loss) # params now have a `.grad` field with the gradient of the loss wrt them.torchjd.autojac.backward: compute jacobians and accumulate them in the.jacfield of the inputs:losses = ... # tensor of shape [m] autojac.backward(losses) # params now have a `.jac` field with the jacobian of the losses wrt them.
Aggregating Jacobians
Now that we’ve computed Jacobians, we can aggregate them so that the optimizer will make an update that doesn’t increase any loss (at least given a sufficiently small learning rate). We call this aggregation rule the Unconflicting Projection of Gradients (UPGrad). To do that, we use torchjd.autojac.jac_to_grad and torchjd.aggregation.UPGrad.
autojac.backward(losses)
# params now have a `.jac` field with the jacobian of the losses wrt them.
jac_to_grad(model.parameters(), UPGrad())
# The `.jac` fields has been replaced by a `.grad` field containing the
# aggregation of the Jacobians. It will be used by the optimizer (SGD, Adam,
# etc.) to update the model parameters.
torchjd.aggregation contains many more aggregators, mostly coming from the multi-task learning literature. The complete list can be found here.
Why not simply averaging the losses?
If you have multiple losses and you average them before making a step of gradient descent on the average loss, you will decrease the average loss but you may increase some individual losses. This is especially true when the gradients of the individual losses conflict (i.e. they have a negative inner product) and their norms are not equal. In contrast, by computing the Jacobian and aggregating it with UPGrad, you make the necessary projections so that the aggregated vector has a positive inner product with every gradient, and thus all losses decrease at the same time. This is illustrated in the following figure, where we compare the aggregation made by UPGrad to the simple averaging of the two gradients, in a context where we have two gradients g1 and g2.
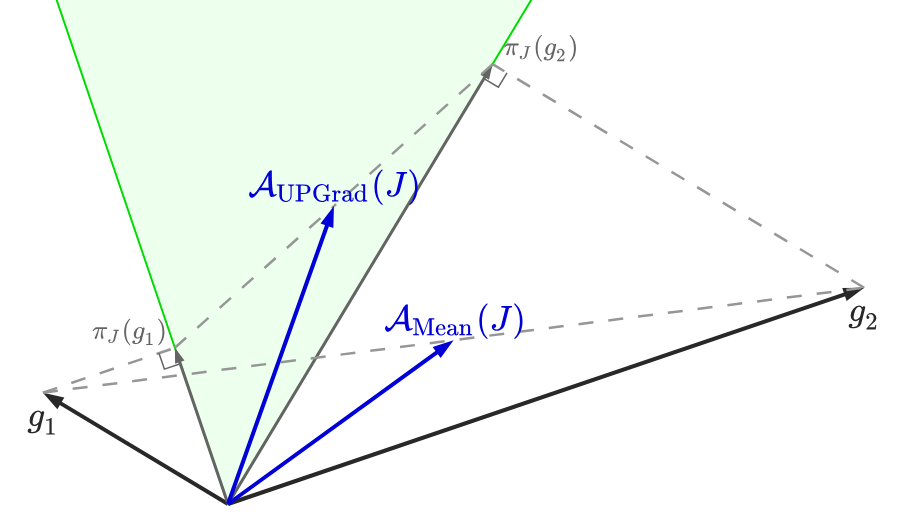
In this example, the average of g1 and g2 has a negative inner product with g1, so averaging the two losses and taking a step of gradient descent would actually increase the first loss.
For a more formal explanations, please refer to our paper.
Links
- GitHub repo: SimplexLab/TorchJD
- Documentation: torchjd.org
- Paper: Jacobian Descent for Multi-Objective Optimization
We’d love to hear some feedback from the community, to help us improve the library. Also, if you want to support us, don’t hesitate to star the repo!
By the way, we recently got accepted at PyTorch conference Europe to make a quick presentation of this project. If you want to attend, see this for more info.