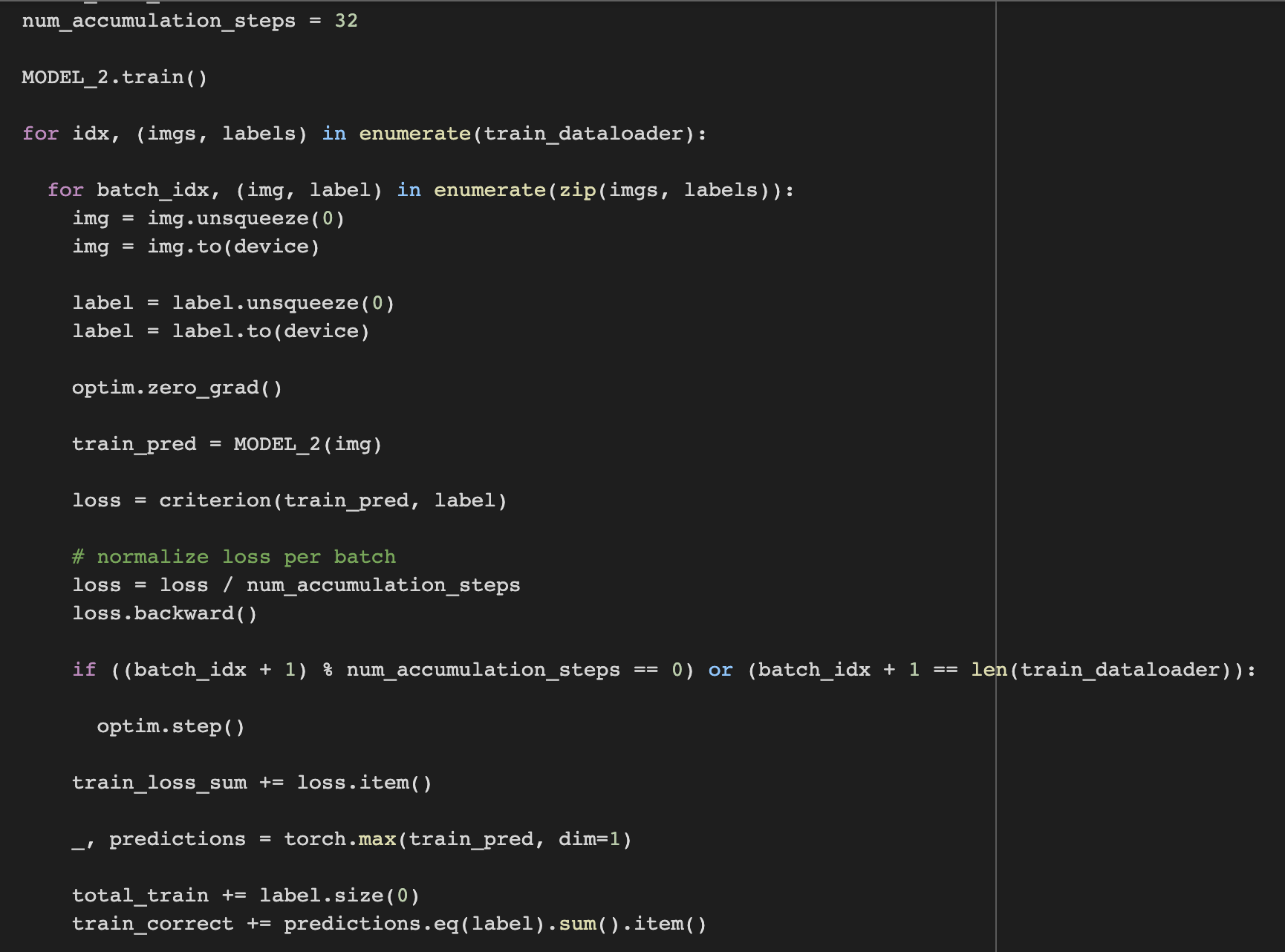
following @SimonW 's answer.
Here is an example of collate_fn:
In this example mask are the mask of the images (that have different sizes). While, data are some cropped windows from the images (the crops have the same size). The idea is to use a list to wrap the data with different sizes.
In your case, the images have different sizes, so you can use the same thing done here for the masks. Need to convert what is needed for the forward to tensors.
def default_collate(batch):
"""
Override `default_collate` https://pytorch.org/docs/stable/_modules/torch/utils/data/dataloader.html#DataLoader
Reference:
def default_collate(batch) at https://pytorch.org/docs/stable/_modules/torch/utils/data/dataloader.html#DataLoader
https://discuss.pytorch.org/t/how-to-create-a-dataloader-with-variable-size-input/8278/3
https://github.com/pytorch/pytorch/issues/1512
We need our own collate function that wraps things up (imge, mask, label).
In this setup, batch is a list of tuples (the result of calling: img, mask, label = Dataset[i].
The output of this function is four elements:
. data: a pytorch tensor of size (batch_size, c, h, w) of float32 . Each sample is a tensor of shape (c, h_,
w_) that represents a cropped patch from an image (or the entire image) where: c is the depth of the patches (
since they are RGB, so c=3), h is the height of the patch, and w_ is the its width.
. mask: a list of pytorch tensors of size (batch_size, 1, h, w) full of 1 and 0. The mask of the ENTIRE image (no
cropping is performed). Images does not have the same size, and the same thing goes for the masks. Therefore,
we can't put the masks in one tensor.
. target: a vector (pytorch tensor) of length batch_size of type torch.LongTensor containing the image-level
labels.
:param batch: list of tuples (img, mask, label)
:return: 3 elements: tensor data, list of tensors of masks, tensor of labels.
"""
data = torch.stack([item[0] for item in batch])
mask = [item[1] for item in batch] # each element is of size (1, h*, w*). where (h*, w*) changes from mask to another.
target = torch.LongTensor([item[2] for item in batch]) # image labels.
return data, mask, target
Instance: dataloader = DataLoader( .... collate_fn=default_collate, ...)
Loop over the data loader:
for img, mask, label in train_loader:
# do stuff.
In the forward function of your model, you need to treat your input as a list.
class myModel(nn.Module):
def forward(self, input):
"""
Classify a list of samples.
:apram input: is a list of n tensors with different height and width ...
:return scores: tensor of scores of shape (n, #nbr_classes)
"""
scores = []
for i, x in enumerate(input):
# x is an image.
score = # forward x
if i == 0:
score = score
else:
scores = torch.cat((scores, score), dim=0)
return scores