torchvision.transforms.v2.Compose with paired transforms like RandomHorizontalFlip and RandomVerticalFlip applies only to the image, not to the mask.
Expected behavior: when using paired transforms and passing a tuple (image, mask), both should be flipped identically.
Observed: only the image is flipped; the mask is unchanged.
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms.v2 import RandomHorizontalFlip, RandomVerticalFlip, Compose
from torchvision.transforms.v2.functional import pil_to_tensor
import matplotlib.pyplot as plt
from PIL import Image, ImageDraw
def create_triangle_image(size=64):
img = Image.new("RGB", (size, size), "black")
draw = ImageDraw.Draw(img)
draw.polygon([(63, 0), (63, 31), (32, 0)], fill="white")
return img
class TriangleDataset(Dataset):
def __init__(self, transform=None):
pil_img = create_triangle_image()
self.img = pil_to_tensor(pil_img)
self.mask = self.img[0].unsqueeze(0) # 1 channel mask
self.transform = transform
def __getitem__(self, idx):
if self.transform:
img_tr, mask_tr = self.transform(self.img, self.mask)
return img_tr, mask_tr
def __len__(self):
return 1
transforms = Compose([
RandomHorizontalFlip(p=.50),
RandomVerticalFlip(p=.50),
])
dataset = TriangleDataset(transform=transforms)
img, mask = next(iter(DataLoader(dataset)))
# Plot
fig, axs = plt.subplots(1, 2, figsize=(6, 3))
axs[0].imshow(img[0].permute(1, 2, 0), cmap='gray')
axs[0].set_title("Image")
axs[1].imshow(mask[0][0], cmap='gray')
axs[1].set_title("Mask")
for ax in axs:
ax.axis("off")
plt.tight_layout()
plt.show()
Results (multiple runs):

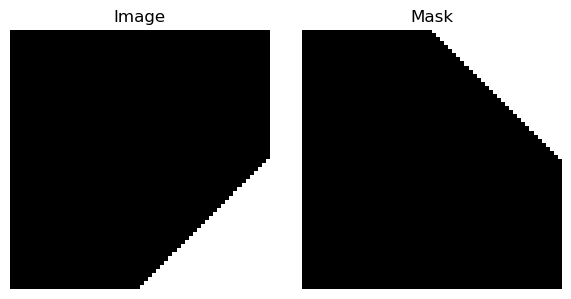
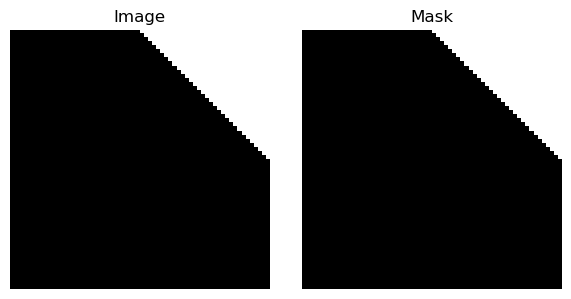
How to fix this?