Hello everyone:
my task is multimodal emotion recognition.
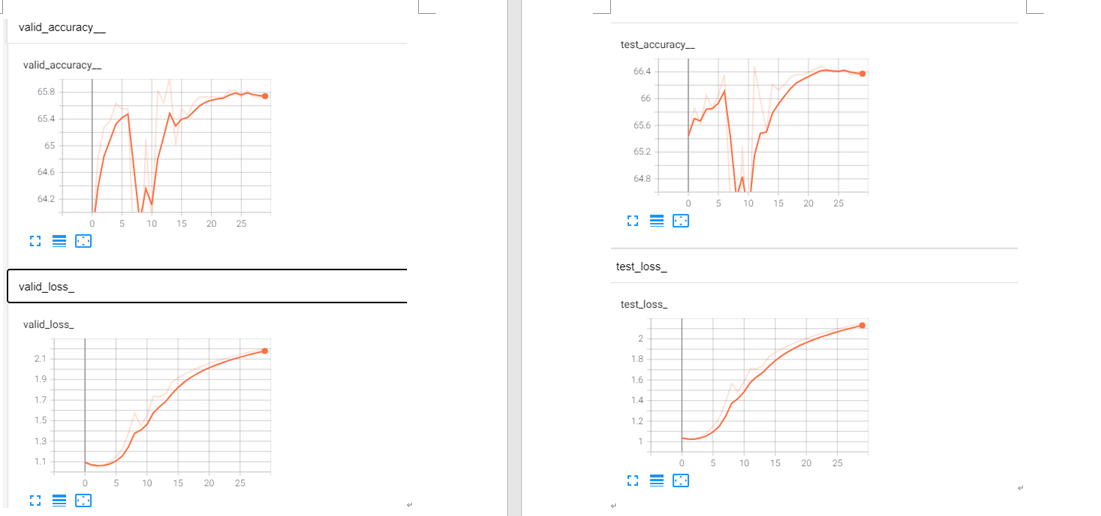
The baseline is only text information, and the current experiment is to fuse the voice information with the text and put it into the original model for training. The basic architecture of the original model is a GRU model with an attention mechanism, the loss function is nn.NLLLoss, and the optimizer is optimizer = optim.Adam(model.parameters(), lr=args.lr, weight_decay=args.l2). But the experimental result is Train accuracy rises, train loss falls, valid test loss rises, valid test accuracy fluctuates.
Here is baseline orignal coding: conv-emotion/COSMIC/erc-training/train_meld.py at master · declare-lab/conv-emotion · GitHub
Could you please give me some details to find the ture error? some suggestion to fix it? Thanks
Here are more detailed informations.
train valid test accuracy loss

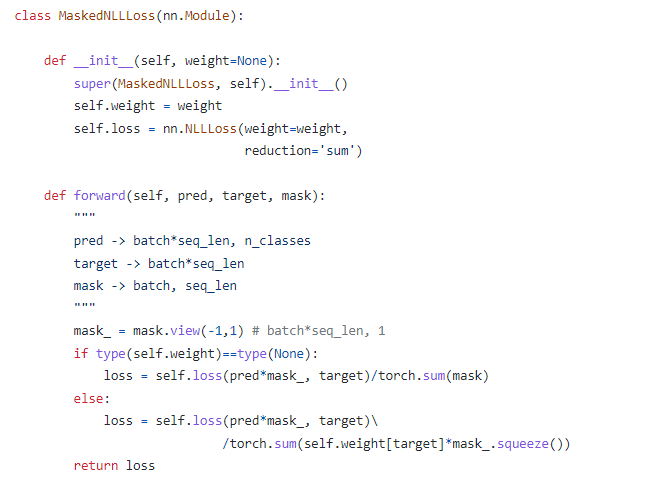
loss function
model summary
CommonsenseGRUModel_bimodal(
(linear_in): Linear(in_features=1024, out_features=300, bias=True)
(norm1a): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm1b): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm1c): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm1d): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm3a): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(norm3b): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(norm3c): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(norm3d): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(dropout): Dropout(p=0.5, inplace=False)
(dropout_rec): Dropout(p=False, inplace=False)
(cs_rnn_f): CommonsenseRNN(
(dropout): Dropout(p=False, inplace=False)
(dialogue_cell): CommonsenseRNNCell(
(g_cell): GRUCell(600, 150)
(p_cell): GRUCell(918, 150)
(r_cell): GRUCell(1218, 150)
(i_cell): GRUCell(918, 150)
(e_cell): GRUCell(750, 450)
(dropout): Dropout(p=False, inplace=False)
(dropout1): Dropout(p=False, inplace=False)
(dropout2): Dropout(p=False, inplace=False)
(dropout3): Dropout(p=False, inplace=False)
(dropout4): Dropout(p=False, inplace=False)
(dropout5): Dropout(p=False, inplace=False)
(attention): SimpleAttention(
(scalar): Linear(in_features=150, out_features=1, bias=False)
)
)
)
(cs_rnn_r): CommonsenseRNN(
(dropout): Dropout(p=False, inplace=False)
(dialogue_cell): CommonsenseRNNCell(
(g_cell): GRUCell(600, 150)
(p_cell): GRUCell(918, 150)
(r_cell): GRUCell(1218, 150)
(i_cell): GRUCell(918, 150)
(e_cell): GRUCell(750, 450)
(dropout): Dropout(p=False, inplace=False)
(dropout1): Dropout(p=False, inplace=False)
(dropout2): Dropout(p=False, inplace=False)
(dropout3): Dropout(p=False, inplace=False)
(dropout4): Dropout(p=False, inplace=False)
(dropout5): Dropout(p=False, inplace=False)
(attention): SimpleAttention(
(scalar): Linear(in_features=150, out_features=1, bias=False)
)
)
)
(sense_gru): GRU(768, 384, bidirectional=True)
(matchatt): MatchingAttention(
(transform): Linear(in_features=900, out_features=900, bias=True)
)
(linear): Linear(in_features=900, out_features=300, bias=True)
(smax_fc): Linear(in_features=300, out_features=7, bias=True)
(linear_in_mixed_feature): Linear(in_features=1408, out_features=300, bias=True)
)