Hi,
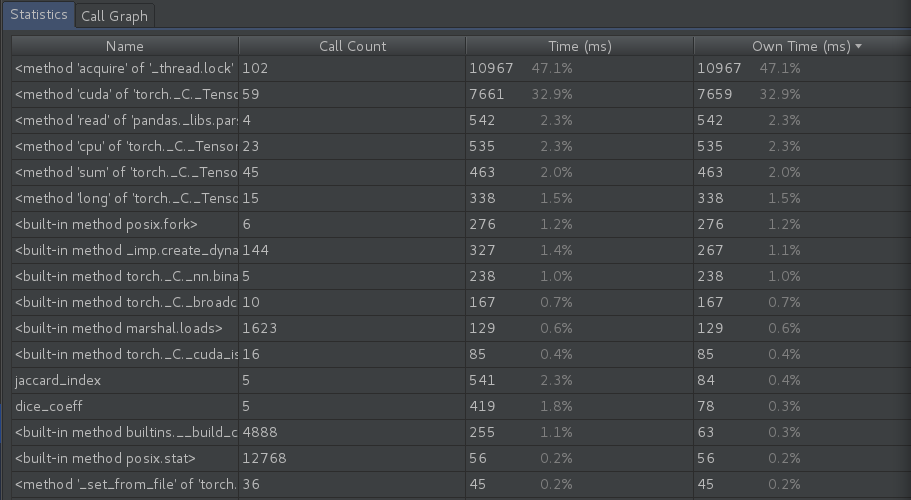
I have a i7 quad-core cpu running at 4.2GHz, with 3 x NVIDIA TITAN V GPUs. While running my training loop for a U-Net model, with the following batch sizes, a performance profile shows that the code spends 62.8% of its time in method acquire of _thread.lock
# training parameters
train:
batch_size: 20
num_workers: 4
# validation parameters
valid:
batch_size: 6
num_workers: 4

Is this somehow PyTorch related, with respect to the DataLoader automatically spinning up worker threads and trying to allocate threads for processing?
Each of my GPUs have 12GB of memory, but they are effectively operating at 1% utilization.
If I reduce the batch size to 1 with 4 workers each, the acquire thread lock still take up most of the time at 50%:
# training parameters
train:
batch_size: 1
num_workers: 4
# validation parameters
valid:
batch_size: 1
num_workers: 4
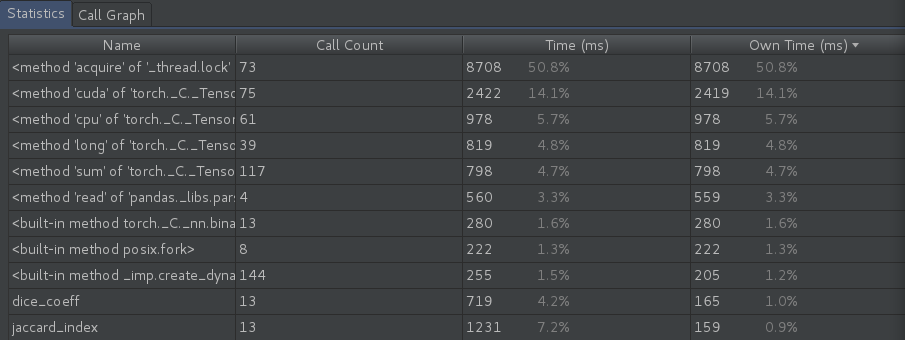
It gets weirder when I reduce both batch size and num of workers to 1, the acquire thread.lock method ends up consuming 71.1% of the total time.
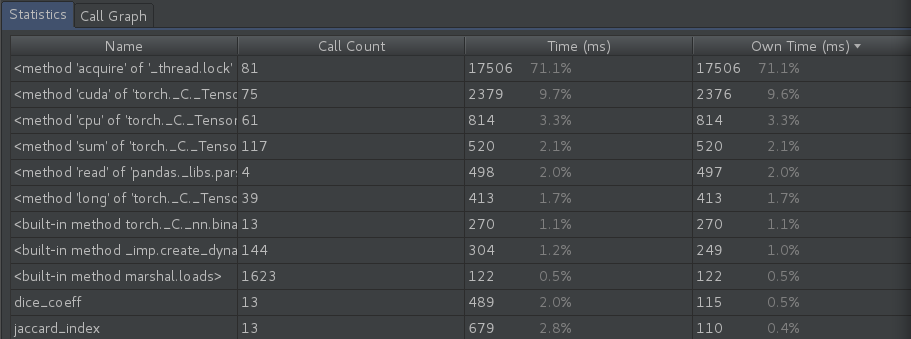
I got better results I matched the number of threads with the number of samples in the batch with the number of GPUs available. The acquire _thread.lock method was at 47.1% with 5.08secs/iteration.
# training parameters
train:
batch_size: 3
num_workers: 3
# validation parameters
valid:
batch_size: 2
num_workers: 2