i debug my model by training many iterations on just one training batch and monitoring the loss achieved on the very batch.
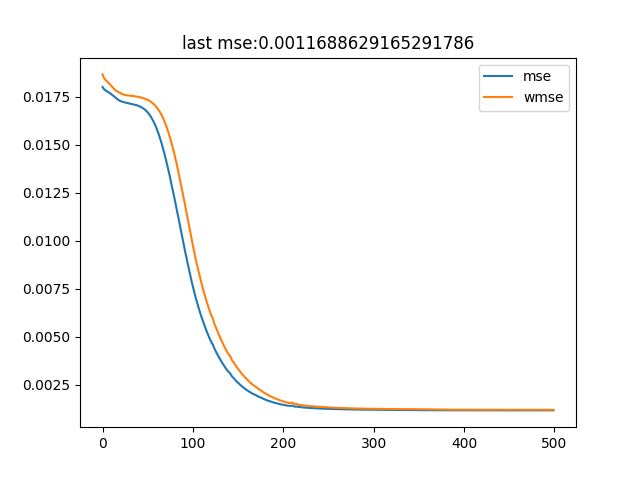
the loss should converge in 0, but clearly doesn’t.
the loss decreases very smooth and just plateaus.
any idea what i am doing wrong?
batch size: 32
task: image super resolution
loss (of interest): mse (mean reduced)
probabilistic modules in network: no (no dropout, noise adding, …)
I don’t see this as totally unexpected or necessarily wrong.
Did you try changing the network architecture? Like adding more layers to it to parameterize it even more – the intuition is maybe the current architecture simply doesn’t have enough parameters to completely fit (all the examples in) this one batch.
Another way to get out of loss stagnation is to fiddle with the learning rate. Maybe try schedulers, lr decay etc.
1 Like
interestingly it plateaus for all learning rates and network widths/depths i tried in the same value (like 2% variance)
lrs i tried : [0.1, 0.01, 0.001, 0.0001, 0.00001, 0.000001]
I see.
A constant loss value implies the network has stopped learning (or is moving at a pace that’s virtually constant). One way to get out of it is to increase the learning rate after a constant loss is observed for a certain no. of epochs (lr scheduling).
Anyway, I would still think that it’s not necessarily incorrect to not be able to obtain exact zero loss on a batch.
1 Like