I cannot post the full code, but i tried to extract the most important parts.
First net:
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.net = nn.Sequential()
self.net.add_module('linear_0', nn.Linear(1152, 460))
self.net.add_module('activation_0', nn.ReLU())
self.net.add_module('bnorm_0', nn.BatchNorm1d(460))
self.net.add_module('linear_1', nn.Linear(460, 115))
self.net.add_module('activation_1', nn.ReLU())
self.net.add_module('bnorm_1', nn.BatchNorm1d(115))
self.net.add_module('linear_2', nn.Linear(115, 460))
self.net.add_module('activation_2', nn.ReLU())
self.net.add_module('bnorm_2', nn.BatchNorm1d(460))
self.net.add_module('linear_3', nn.Linear(460, 1152))
self.net.add_module('activation_3', nn.ReLU())
self.net.add_module('bnorm_3', nn.BatchNorm1d(1152))
def forward(self, x):
return self.net(x)
Second net:
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
self.net = nn.Sequential()
self.net.add_module('linear_0', nn.Linear(1152, 2048))
self.net.add_module('activation_0', nn.ReLU())
self.net.add_module('bnorm_0', nn.BatchNorm1d(2048))
self.net.add_module('linear_1', nn.Linear(2048, 2048))
self.net.add_module('activation_1', nn.ReLU())
self.net.add_module('bnorm_1', nn.BatchNorm1d(2048))
self.net.add_module('linear_2', nn.Linear(2048, 2048))
self.net.add_module('activation_2', nn.ReLU())
self.net.add_module('bnorm_2', nn.BatchNorm1d(2048))
self.net.add_module('linear_3', nn.Linear(2048, 2048))
self.net.add_module('activation_3', nn.ReLU())
self.net.add_module('bnorm_3', nn.BatchNorm1d(2048))
self.net.add_module('linear_4', nn.Linear(2048, 2048))
self.net.add_module('activation_4', nn.ReLU())
self.net.add_module('bnorm_4', nn.BatchNorm1d(2048))
self.net.add_module('linear_5', nn.Linear(2048, 2048))
self.net.add_module('activation_5', nn.ReLU())
self.net.add_module('bnorm_5', nn.BatchNorm1d(2048))
self.net.add_module('linear_6', nn.Linear(2048, 2040))
self.net.add_module('softmax', nn.Softmax())
def forward(self, x):
return self.net(x)
Chaining both:
class Chain(nn.Module):
def __init__(self, transformer_model, classification_model):
super(Chain, self).__init__()
self.transformer = transformer_model
self.classifier = classification_model
def forward(self, data):
# compute transformer output
output = self.transformer.forward(data)
# compute classifier output
output = self.classifier.forward(output)
return output
def train(self, mode=True):
self.training = mode
self.transformer.train(mode=mode)
self.classifier.train(mode=False)
Now i create the models as follows, the second one is already trained and works as expected (standalone):
model = tr_fix.Transformer()
sc_model = sc_fix.Classifier()
sc_model.load_state_dict(torch.load(sc_model_state_path))
full_model = state_back_fix.Chain(model, sc_model)
Set requires_grad to false:
for param in full_model.classifier.parameters():
param.requires_grad = False
Optim and loss:
loss_func = torch.nn.BCELoss()
optimizer = optim.Adam(full_model.transformer.parameters(), lr=0.001)
Then i train that thing using a library i wrote for convenience:
trainer = candle.Trainer(full_model, optimizer,
targets=[candle.Target(loss_func, loss_func)],
num_epochs=10,
use_cuda=True)
train_log = trainer.train(train_loader, dev_loader)
eval_log = trainer.evaluate(test_loader)
train/dev/test_loader are custom pytorch dataloaders. The important part from the Trainer you can find here:
return iteration_log
def train_epoch(self, epoch_index, train_loader, dev_loader=None):
"""
Run one epoch of training. Returns a iteration log.
Arguments:
epoch_index (int): An index that identifies the epoch.
train_loader (torch.utils.data.DataLoader): PyTorch loader that provides training data.
dev_loader (torch.utils.data.DataLoader): PyTorch loader that provides validation data.
Returns:
IterationLog: The iteration log.
"""
iteration_log = log.IterationLog(targets=self._targets, metrics=self._metrics)
self._model.train()
self._callback_handler.notify_before_train_epoch(epoch_index, iteration_log)
for batch_index, batch in enumerate(train_loader):
Thanks already for confirming that i am not totally wrong.
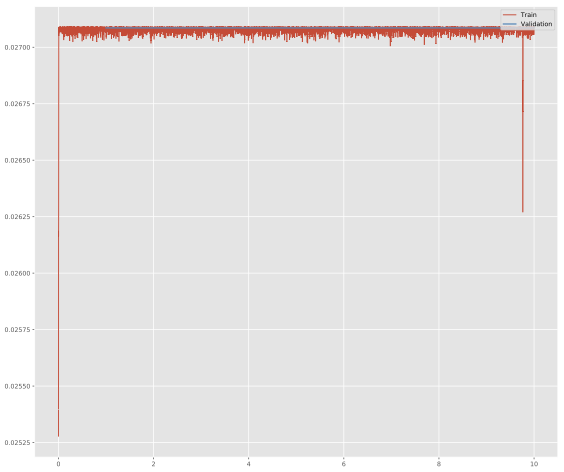
Furthermore the loss i get looks like that: