Hi There,
Suppose I have two training dataset with different size and I am trying to train it on a network simultaneously, So I can do it? also, I need to keep a track of from which dataset image is coming to find out the loss after each iteration by the equation:
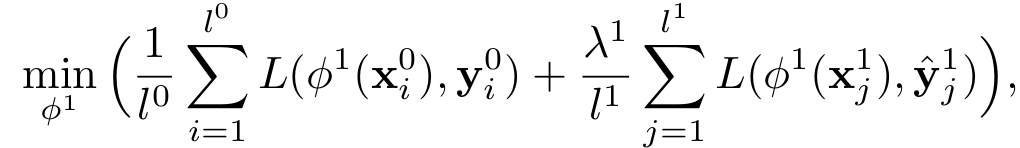
where,
L0 & L1 are the lengths of the dataset and Lambda is a balancing constant.
Thank you.