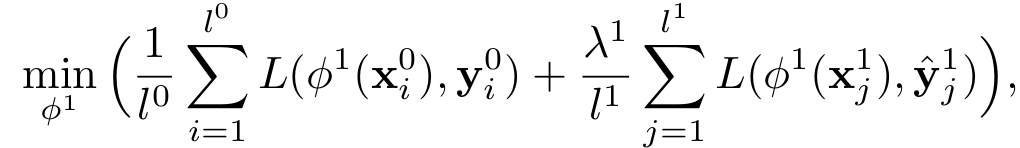Hi there, I have managed to use two datasets by creating a custom dataset that takes in two root directories:
class dataset_maker(Dataset):
def __init__(self, root_dir1, root_dir2, transform= None):
self.root_dir1=root_dir1
self.root_dir2=root_dir2
self.filelist1 = glob.glob(root_dir1+'*.png')
self.filelist2 = glob.glob(root_dir2+'*.png')
self.transform=transform
def __len__(self):
return min(len(self.filelist1),len(self.filelist2))
def __getitem__(self, idx):
sample1 = io.imread(self.filelist1[idx])/65535*255
sample2 = io.imread(self.filelist2[idx])/65535*255
sample1=np.uint8(sample1)
sample2=np.uint8(sample2)
sample1=PIL.Image.fromarray(sample1)
sample2=PIL.Image.fromarray(sample2)
if self.transform:
sample1 = self.transform(sample1)
sample2 = self.transform(sample2)
return sample1,sample2
then, make a dataloader using the two datasets:
dataloader = DataLoader(combined_dataset, batch_size=3, shuffle=True, num_workers=4)
Finally, I get the data in the training loops by doing this call in the for loop:
for epoch in range(10):
running_loss=0.0
#get the data
for batch_num, (hq_batch,Lq_batch) in enumerate(dataloader):
print(batch_num, hq_batch.shape, Lq_batch.shape)
The output is stated below:
0 torch.Size([3, 3, 256, 256]) torch.Size([3, 3, 256, 256])
1 torch.Size([3, 3, 256, 256]) torch.Size([3, 3, 256, 256])
2 torch.Size([3, 3, 256, 256]) torch.Size([3, 3, 256, 256])
3 torch.Size([3, 3, 256, 256]) torch.Size([3, 3, 256, 256])
4 torch.Size([3, 3, 256, 256]) torch.Size([3, 3, 256, 256])
5 torch.Size([3, 3, 256, 256]) torch.Size([3, 3, 256, 256])
6 torch.Size([3, 3, 256, 256]) torch.Size([3, 3, 256, 256])
7 torch.Size([3, 3, 256, 256]) torch.Size([3, 3, 256, 256])
8 torch.Size([3, 3, 256, 256]) torch.Size([3, 3, 256, 256])
9 torch.Size([3, 3, 256, 256]) torch.Size([3, 3, 256, 256])
10 torch.Size([3, 3, 256, 256]) torch.Size([3, 3, 256, 256])
11 torch.Size([3, 3, 256, 256]) torch.Size([3, 3, 256, 256])
12 torch.Size([3, 3, 256, 256]) torch.Size([3, 3, 256, 256])
Hope this solves the problem!