Ok I agree. I wanted to go back to the drawing board and start with a model which I want to intentionally over fit (given, I have only 100 images, 50 per class that should not be a too difficult task, or at least that is what I thought). To prove that it can learn something. So I will detail what is happening here.
Case -1
Model -
class Reshape(torch.nn.Module):
def forward(self, x):
return x.reshape(-1, 64 * 7 * 7)
model_conv = nn.Sequential(nn.Conv2d(3, 8, kernel_size=3, padding=1), nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(8, 16, kernel_size=3, padding=1), nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(16, 32, kernel_size=3, padding=1), nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(32, 64, kernel_size=3, padding=1), nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
Reshape(),
nn.Linear(3136, 256), nn.ReLU(),
nn.Linear(256, 128), nn.ReLU(),
nn.Linear(128, 84), nn.ReLU(),
nn.Linear(84, 2)
)
Transforms-
data_transforms = {
'train': transforms.Compose([
transforms.Resize((120, 120)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
]),
'test': transforms.Compose([
transforms.Resize((120, 120)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
]),
}
As you may see, I had not put any Dropout or any standard regularization technique so that I give it all chances to over-fit.
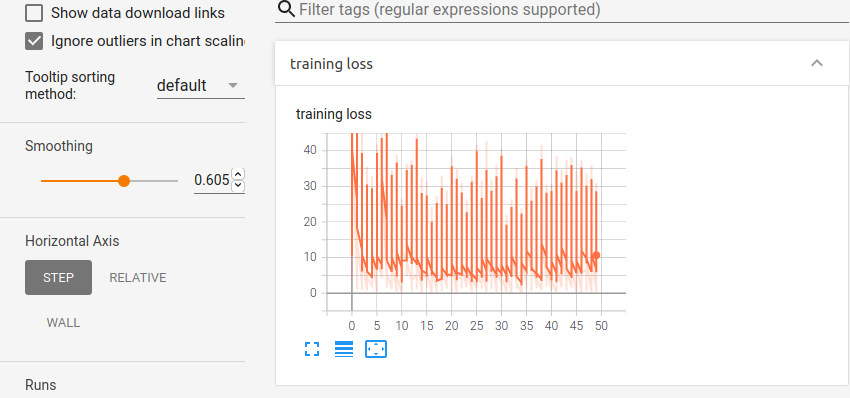
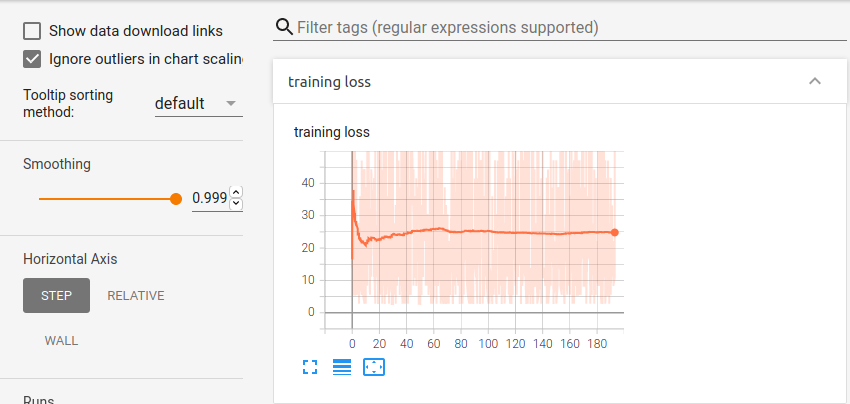
This is the loss curve looks like -
So the loss hits a plateau very soon and never decreases. (The loss is pretty bigger too)
Also, this is the lr - optimizer_conv = optim.SGD(model_conv.parameters(), lr=0.01, momentum=0.9)
And a scheduler for lr - exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)
Case 2
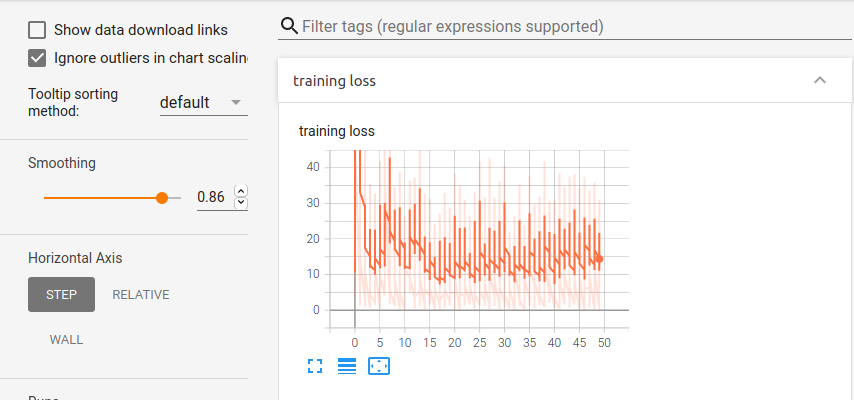
Same model, just changing the lr
optimizer_conv = optim.SGD(model_conv.parameters(), lr=0.001, momentum=0.9)
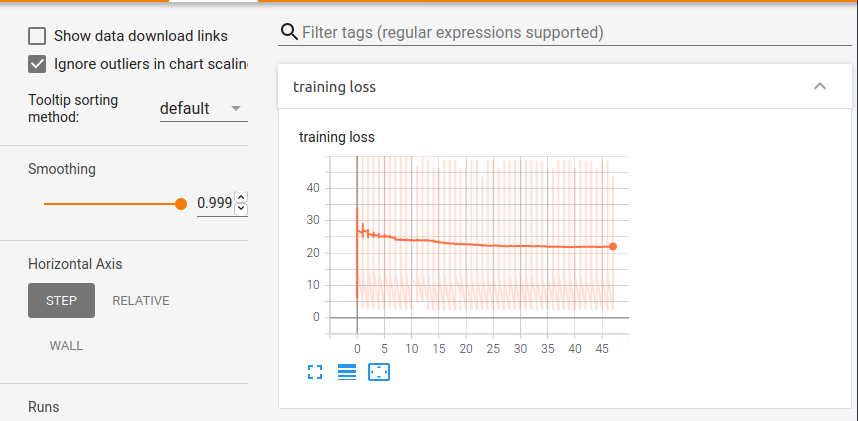
Which keeps it very similar (from the numbers printed it does seem like the val loss and acc both are worse than last time though) -
** Case 3**
Here I go for a simpler model
Model -
class Reshape(torch.nn.Module):
def forward(self, x):
return x.reshape(-1, 16 * 30 * 30)
model_conv = nn.Sequential(nn.Conv2d(3, 8, kernel_size=3, padding=1), nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(8, 16, kernel_size=3, padding=1), nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
Reshape(),
nn.Linear(14400, 256), nn.ReLU(),
nn.Linear(256, 84), nn.ReLU(),
nn.Linear(84, 2)
)
The LR is - optimizer_conv = optim.SGD(model_conv.parameters(), lr=0.001, momentum=0.9)
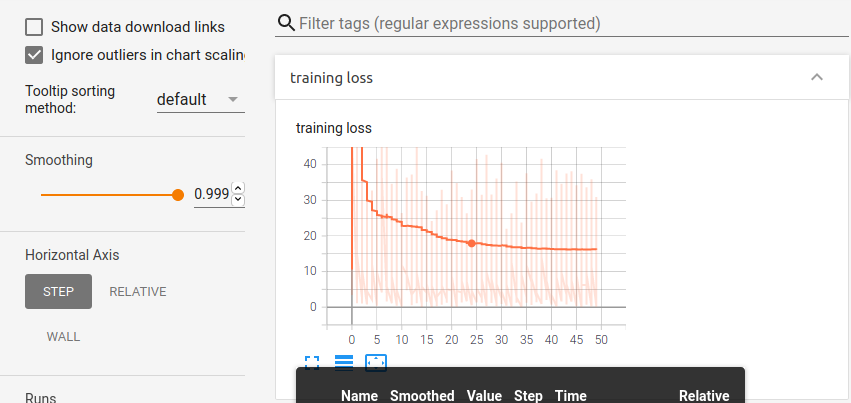
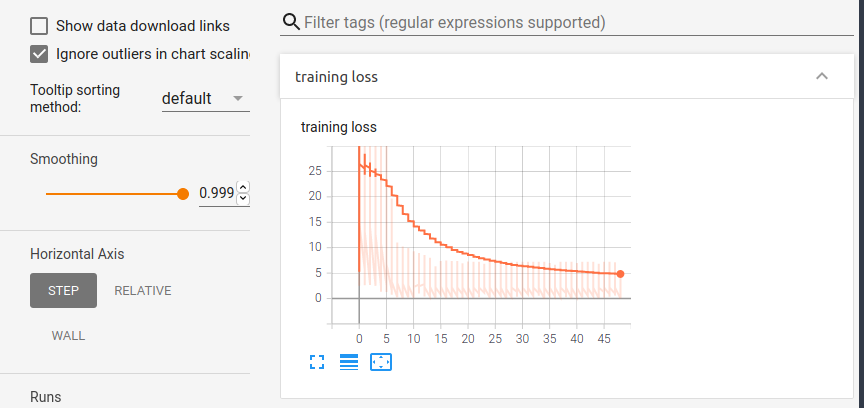
Here I experience something strange. For some runs of the whole code a graph like this will be produced -
Where the loss decrease is not really seen.
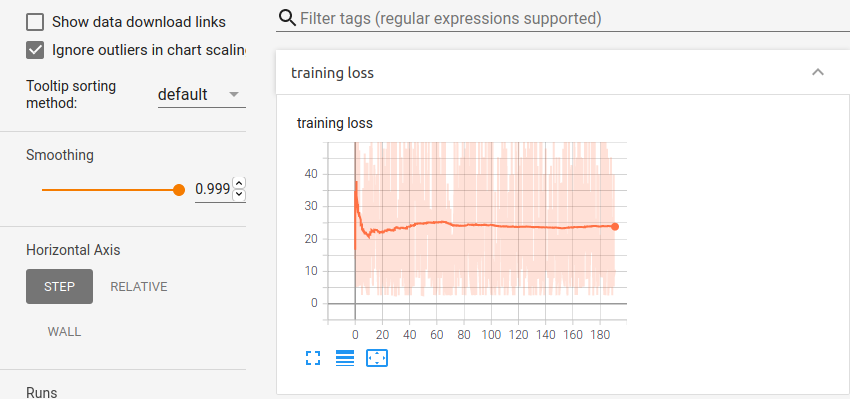
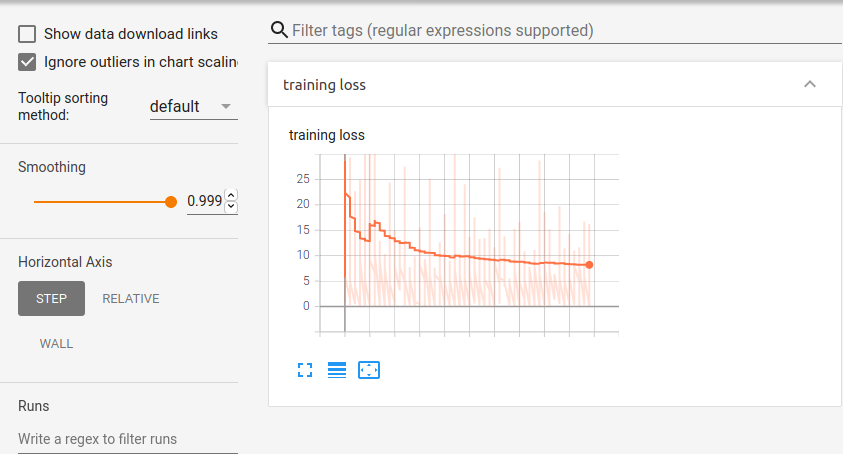
But for some others. The following kind of graph will be produced.
Which shows that the loss is decreasing well. And also the validation acc reaches 100% (larger than the test one!)
What is wrong here you think? Why the network before was not able to over-fit the data?
Also, an interesting insight is that, on the exact same data-set a HOG-SVM classical model reaches about 95% acc with a bit of effort.
So makes me think that whether I need more data. However, I would have expected using a CNN as a fixed feature extraction should have given me a great result.
Another update is with the new transform (120, 120) the restnet fine tuning is actually going much better  I guess with a 32 x 32 (the resize transform I had before) was too small to distinguish between two images which is really close to each other from look and feel. This is the loss curve when I train the final layer of resnet18 in this new setting -
I guess with a 32 x 32 (the resize transform I had before) was too small to distinguish between two images which is really close to each other from look and feel. This is the loss curve when I train the final layer of resnet18 in this new setting -
Another update, some experiments with lr (0.01) and my first model shows that sometimes The loss does decrease. Sometimes not. That can even happen in two consecutive runs. This does not make sense to me. Why the behavior is not consistent if everything else stays the same? What am I missing here?