I am trying to combine 2 models sequentially like one’s output is another’s input.
But second one which creates final output is pre-trained model and it will be trained no more. I only wants to train first one.
It is easier to understand with the picture.
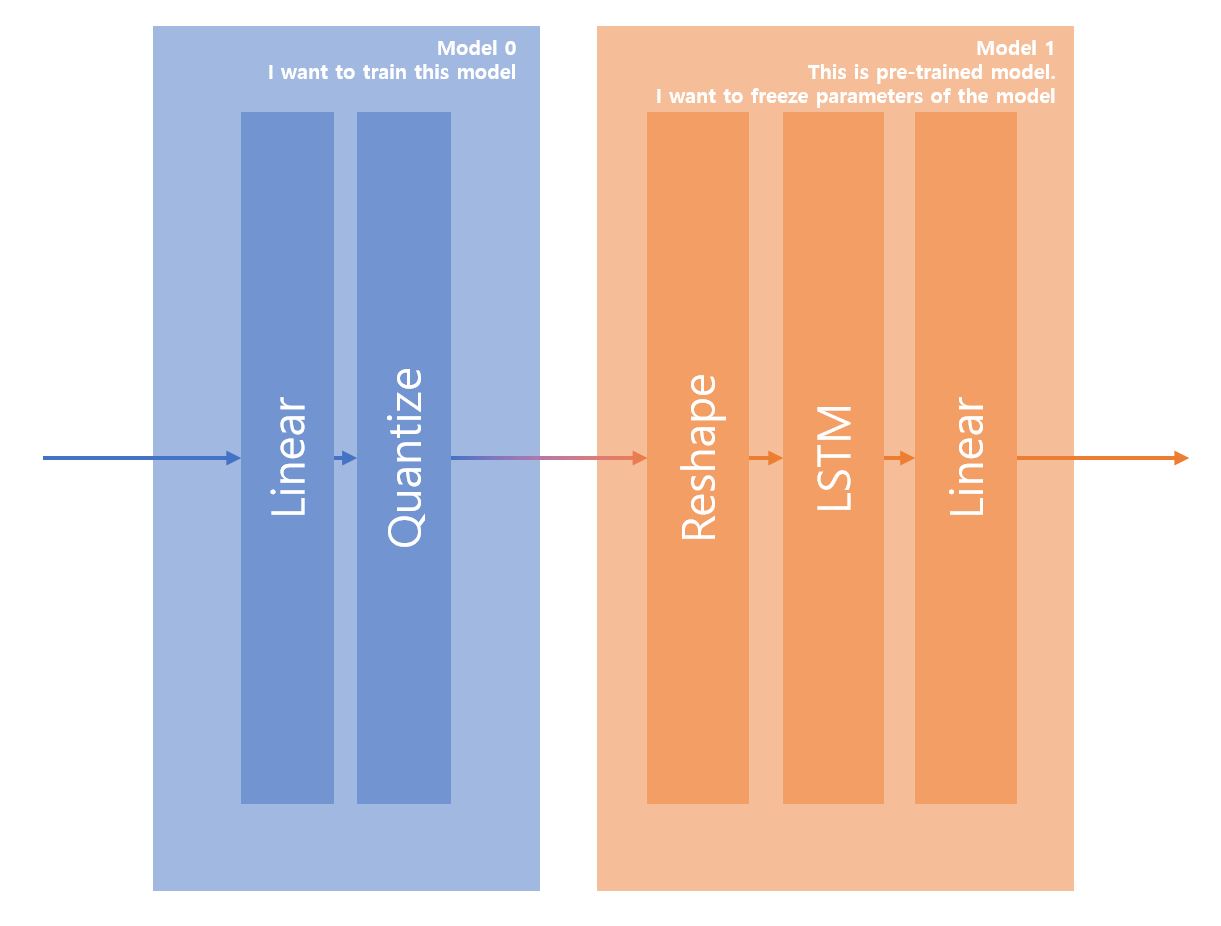
One model has architecture below,
class LinearModel(nn.Module):
def __init__(self, bias=True):
super(LinearModel, self).__init__()
self.bias = bias
self.linear0 = nn.Linear(64, 64, bias=bias)
self.quantize = QuantizeLayer(num_bits=8)
def forward(self, x):
linear0_out = self.linear0(x)
quant_out = self.quantize(linear0_out)
return quant_out
And it has a ‘QuantizeLayer’ which I have made.
class Quantize(torch.autograd.Function):
@staticmethod
def forward(ctx, input, scale, quant_min, quant_max):
rounded_input = torch.round(input*scale) / scale
return torch.clamp(rounded_input, min=quant_min, max=quant_max)
@staticmethod
def backward(ctx, grad_output):
grad_input = grad_output.clone()
return grad_input, None, None, None
class QuantizeLayer(nn.Module):
def __init__(self, num_bits=8):
super(QuantizeLayer, self).__init__()
self.scale = 2 ** num_bits
self.quant_min = -1
self.quant_max = 1 - (2**-(num_bits-1))
self.quantize = Quantize.apply
def forward(self, x):
return self.quantize(x, self.scale, self.quant_min, self.quant_max)
The other model has architecture below,
class LSTMModel(nn.Module):
def __init__(self):
super(LSTMModel, self).__init__()
input_size=1
hidden_size=256
num_layers=1
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.linear = nn.Linear(hidden_size, 1)
def forward(self, x):
reshaped = torch.reshape(x, (-1, 64, 1))
lstm_out, _ = self.lstm(reshaped)
lstm_out = lstm_o[:,-1]
linear_out = self.linear(lstm_out)
return linear_out
And I wrapped up those two models like below,
class CombinedModel(nn.Module):
def __init__(self, model0, model1):
super(CombinedModel, self).__init__()
self.model0 = model0
for param in model1.parameters():
param.requires_grad = False
self.model1 = model1
def forward(self, x):
x = self.model0(x)
x = self.model1(x)
return x
Finally, I trained the model with dummy data to find out it is working or not.
To check out, I compared all parameters before training and after training.
# Dummy data for data, labels
x = torch.rand((1000, 64))
y = torch.rand((1000, 1))
# Model objects
linearModel = LinearModel()
lstmModel = LSTMModel()
combinedModel = CombinedModel(linearModel, lstmModel)
# Parameter before training
state_dict_before = {}
for layer in combinedModel.state_dict():
state_dict_before[layer] = combinedModel.state_dict()[layer].numpy()
# Training
criterion = nn.MSELoss()
optimizer = optim.SGD(combinedModel.parameters(), lr=1e-2)
combinedModel.train()
for i in range(10):
pred = combinedModel(x)
loss = criterion(pred, y)
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Parameter after training
state_dict_after = {}
for layer in combinedModel.state_dict():
state_dict_after[layer] = combinedModel.state_dict()[layer].numpy()
# Compare parameter before training and after training
for layer in state_dict_before:
print(np.equal(state_dict_before[layer], state_dict_after[layer]).all())
And all parameters are the same.
So I checked that gradients are really passing through the model while training by printing out “grad_out” and “grad_in” from ‘Quantize::backward()’. And it was not all-zero tensor.
I am digging whole day try to find out what went wrong. But I couldn’t figured out. ;(