Hi
My dataset consist of 3000 files, 1000 files from 3 classes. I use the pytorch data module data.Dataset:
class passengerShipDataset(data.Dataset):
def __init__(self, root_dir):
self.list_of_data_files = glob.glob(root_dir)
self.len = len(self.list_of_data_files)
def __getitem__(self, index):
single_track = torch.from_numpy(np.transpose(genfromtxt(self.list_of_data_files[index], delimiter=','))[:,1:])
target = np.zeros(single_track.size(1))
target[:] = 1
target = torch.from_numpy(target) #passenger
return (single_track, target)
def __len__(self):
return self.len
I have three of these datasets, and then combine them into a single dataset using:
allShips = data.ConcatDataset([cargoShips, passengerShips, fishingShips])
train_set_all = data.DataLoader(dataset=allShips,batch_size=1,shuffle=True)
This will load one track at a time. Each track is of different length. One track is 3 channels: [Lat, lon, time]. I then want to run the track trough a CNN to extract features and then feed these features to a RNN to classify the track. However, I want to feed only one timestep at a time to my network not the entire sequence.
The idea is that with timestep 1 the network will classify uniformly like 33% on each class. Then at each consecutive timestep it becomes better and better at classifying the track.
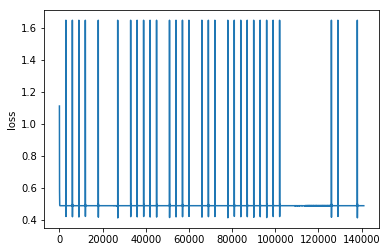
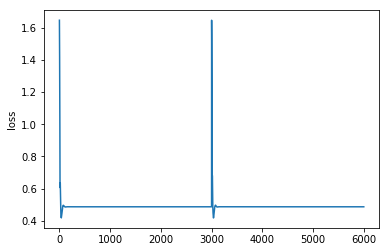
When i train my network i see the loss fall throughout the first few 100-1000 timesteps on a track and then the loss stays constant. At the next track, the loss resets back to high and then again falls in the first 100-1000 timesteps. This continues on forever through all tracks as if the network learns nothing.
Then when i test my network it is only good at classifying one class (the last trained upon) and i get accuracy 30%.
I want the loss to fall over several tracks not through each individual track. Is there a way to run a track through the network one step at a time and only calculate loss in the end of the track?
Right now its like my network receives “track length” samples of one class and then become very good at classifying that class. But I want my network to see each track as a sample and not as if its “track length” samples.
I think the problem is that data is not “shuffled” because it sees one track as many samples of a single class. I can’t seem to find any solution to this because one track is one class. And i want to find features within a track so i cannot simply feed one timestep from one track and then one timestep from another track.