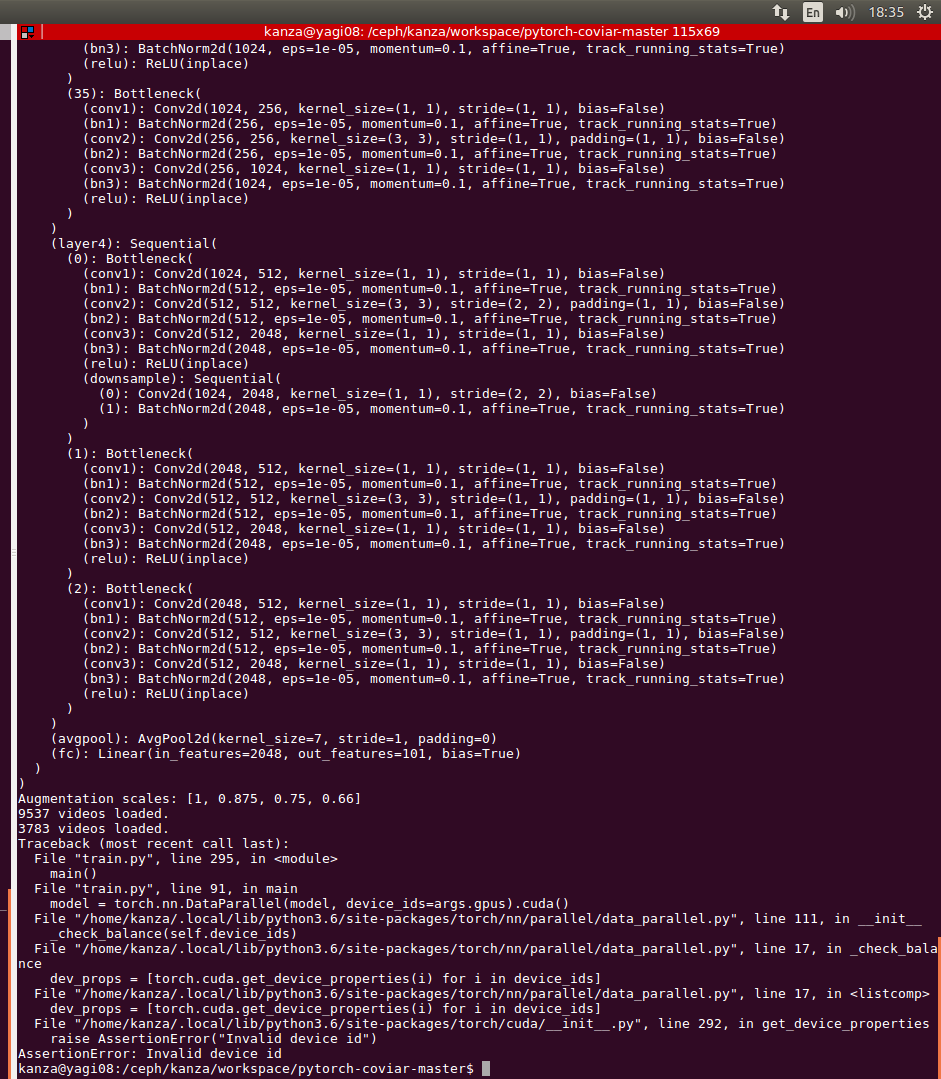
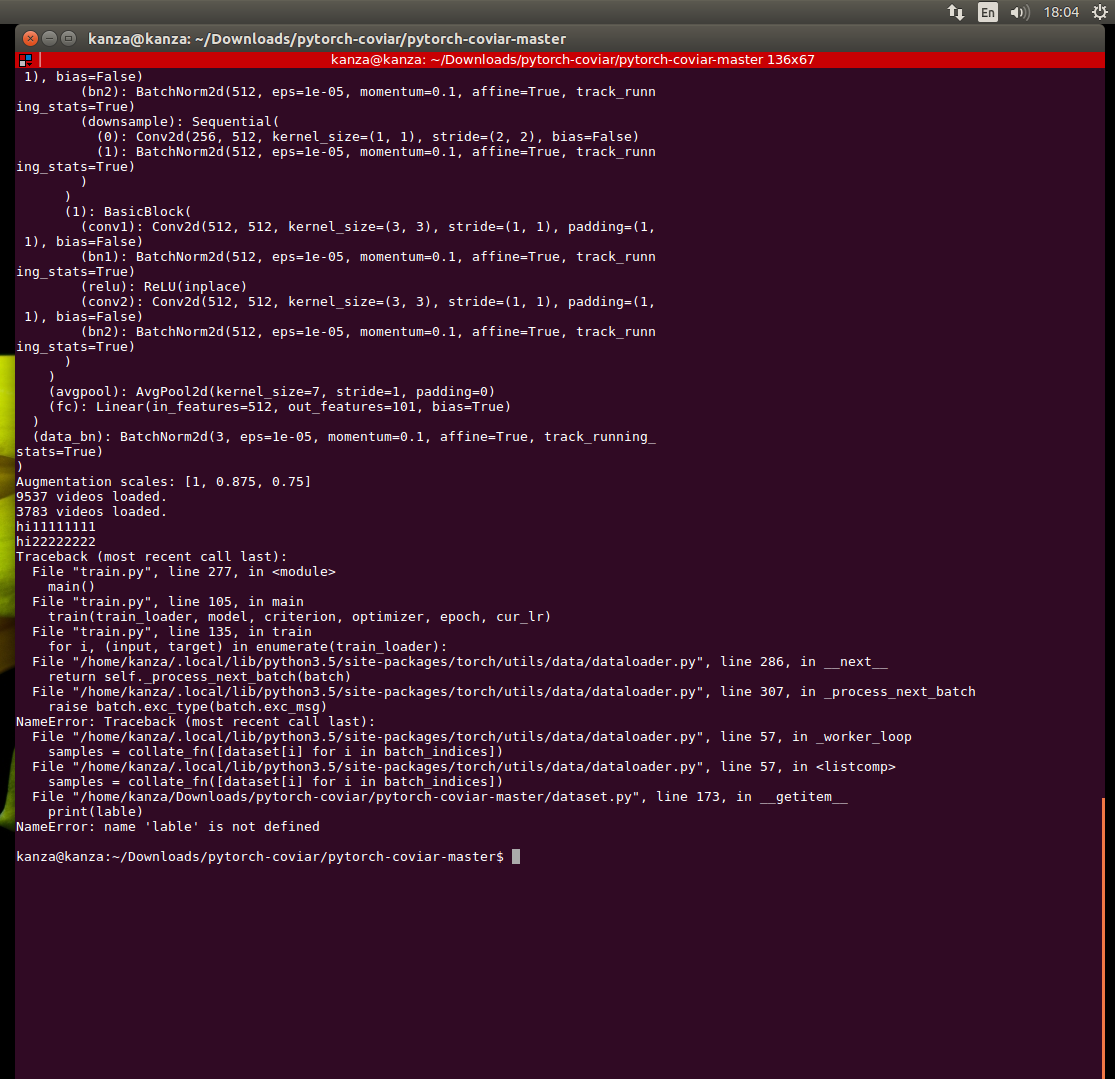
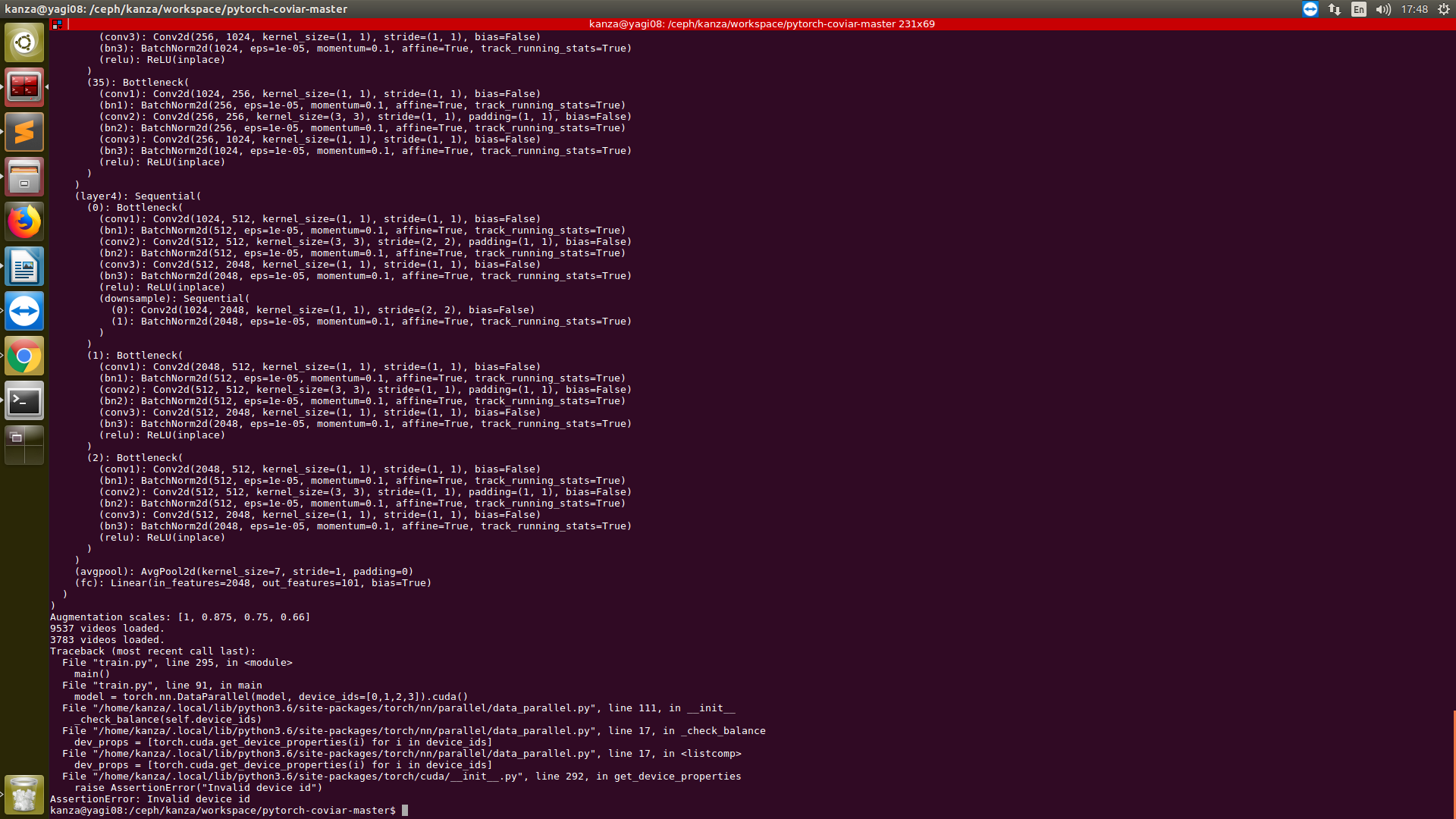
Label is now printing labels with error:
Traceback (most recent call last):
File “train.py”, line 273, in
main()
File “train.py”, line 102, in main
train(train_loader, model, criterion, optimizer, epoch, cur_lr)
File “train.py”, line 140, in train
output = model(input_var)
File “/home/kanza/.local/lib/python3.5/site-packages/torch/nn/modules/module.py”, line 491, in call
result = self.forward(*input, **kwargs)
File “/home/kanza/.local/lib/python3.5/site-packages/torch/nn/parallel/data_parallel.py”, line 112, in forward
return self.module(*inputs[0], **kwargs[0])
File “/home/kanza/.local/lib/python3.5/site-packages/torch/nn/modules/module.py”, line 491, in call
result = self.forward(*input, **kwargs)
File “/home/kanza/Downloads/pytorch-coviar/pytorch-coviar-master/model.py”, line 64, in forward
base_out = self.base_model(input)
File “/home/kanza/.local/lib/python3.5/site-packages/torch/nn/modules/module.py”, line 491, in call
result = self.forward(*input, **kwargs)
File “/home/kanza/.local/lib/python3.5/site-packages/torchvision/models/resnet.py”, line 144, in forward
x = self.layer1(x)
File “/home/kanza/.local/lib/python3.5/site-packages/torch/nn/modules/module.py”, line 491, in call
result = self.forward(*input, **kwargs)
File “/home/kanza/.local/lib/python3.5/site-packages/torch/nn/modules/container.py”, line 91, in forward
input = module(input)
File “/home/kanza/.local/lib/python3.5/site-packages/torch/nn/modules/module.py”, line 491, in call
result = self.forward(*input, **kwargs)
File “/home/kanza/.local/lib/python3.5/site-packages/torchvision/models/resnet.py”, line 88, in forward
residual = self.downsample(x)
File “/home/kanza/.local/lib/python3.5/site-packages/torch/nn/modules/module.py”, line 491, in call
result = self.forward(*input, **kwargs)
File “/home/kanza/.local/lib/python3.5/site-packages/torch/nn/modules/container.py”, line 91, in forward
input = module(input)
File “/home/kanza/.local/lib/python3.5/site-packages/torch/nn/modules/module.py”, line 491, in call
result = self.forward(*input, **kwargs)
File “/home/kanza/.local/lib/python3.5/site-packages/torch/nn/modules/batchnorm.py”, line 49, in forward
self.training or not self.track_running_stats, self.momentum, self.eps)
File “/home/kanza/.local/lib/python3.5/site-packages/torch/nn/functional.py”, line 1194, in batch_norm
training, momentum, eps, torch.backends.cudnn.enabled
RuntimeError: cuda runtime error (2) : out of memory at /pytorch/aten/src/THC/generic/THCStorage.cu:58