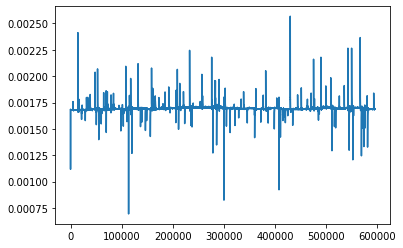
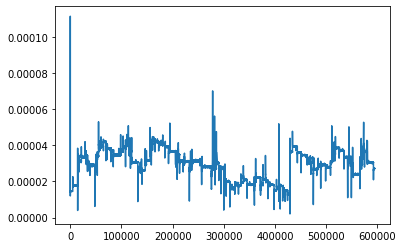
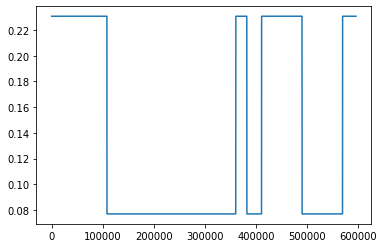
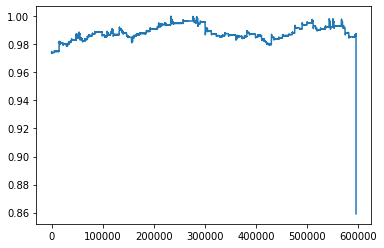
Above, I’m using the input data as target, so purely reconstruction, but I do get what you’re saying. Makes absolute sense. However, the normalization is category-wise. So even though the current and voltage are very small (in this example), there are other examples where the signal reaches 1.
I was trying to change the training targets, from reconstruction to actual prediction tasks (generators, transformers, loads, cables → voltage/current).
Still, the same learning outcome; overfits pretty quickly after only a few hundred batches.
I simulated the data again, and this time, made it 8x more complex (in terms of less steady states), but the outcome is still similar.
I have also capped (torch.clamp) the KL divergence loss term at min=0.1, otherwise, it would go negative. Here’s again the latest run:
Batch [1/14999], Batch Training Loss: 3.3345
Batch [2/14999], Batch Training Loss: 3.1343
Batch [3/14999], Batch Training Loss: 2.9440
Batch [4/14999], Batch Training Loss: 2.7247
Batch [5/14999], Batch Training Loss: 2.4829
Batch [6/14999], Batch Training Loss: 2.2184
Batch [7/14999], Batch Training Loss: 1.8933
Batch [8/14999], Batch Training Loss: 1.5799
Batch [9/14999], Batch Training Loss: 1.2666
Batch [10/14999], Batch Training Loss: 0.8640
Batch [11/14999], Batch Training Loss: 0.6118
Batch [12/14999], Batch Training Loss: 0.3489
Batch [13/14999], Batch Training Loss: 0.1858
Batch [14/14999], Batch Training Loss: 0.0420
Batch [15/14999], Batch Training Loss: 0.0355
Batch [16/14999], Batch Training Loss: 0.0321
Batch [17/14999], Batch Training Loss: 0.0269
Batch [18/14999], Batch Training Loss: 0.0233
Batch [19/14999], Batch Training Loss: 0.0214
Batch [20/14999], Batch Training Loss: 0.0197
Batch [21/14999], Batch Training Loss: 0.0196
Batch [22/14999], Batch Training Loss: 0.0202
Batch [23/14999], Batch Training Loss: 0.0206
Batch [24/14999], Batch Training Loss: 0.0186
Batch [25/14999], Batch Training Loss: 0.0957
Batch [26/14999], Batch Training Loss: 0.0159
Batch [27/14999], Batch Training Loss: 0.0149
Batch [28/14999], Batch Training Loss: 0.0143
Batch [29/14999], Batch Training Loss: 0.0143
Batch [30/14999], Batch Training Loss: 0.0143
Batch [31/14999], Batch Training Loss: 0.0137
Batch [32/14999], Batch Training Loss: 0.0138
Batch [33/14999], Batch Training Loss: 0.0132
Batch [34/14999], Batch Training Loss: 0.0141
Batch [35/14999], Batch Training Loss: 0.0132
Batch [36/14999], Batch Training Loss: 0.0129
Batch [37/14999], Batch Training Loss: 0.0133
Batch [38/14999], Batch Training Loss: 0.0137
Batch [39/14999], Batch Training Loss: 0.0130
Batch [40/14999], Batch Training Loss: 0.0128
Batch [41/14999], Batch Training Loss: 0.0126
Batch [42/14999], Batch Training Loss: 0.0125
Batch [43/14999], Batch Training Loss: 0.0128
Batch [44/14999], Batch Training Loss: 0.0126
Batch [45/14999], Batch Training Loss: 0.0123
Batch [46/14999], Batch Training Loss: 0.0122
Batch [47/14999], Batch Training Loss: 0.0119
Batch [48/14999], Batch Training Loss: 0.0120
Batch [49/14999], Batch Training Loss: 0.0119
Batch [50/14999], Batch Training Loss: 0.0120
Batch [51/14999], Batch Training Loss: 0.0117
Batch [52/14999], Batch Training Loss: 0.0118
Batch [53/14999], Batch Training Loss: 0.0119
Batch [54/14999], Batch Training Loss: 0.0116
Batch [55/14999], Batch Training Loss: 0.0118
Batch [56/14999], Batch Training Loss: 0.0114
Batch [57/14999], Batch Training Loss: 0.0115
Batch [58/14999], Batch Training Loss: 0.0116
Batch [59/14999], Batch Training Loss: 0.0115
Batch [60/14999], Batch Training Loss: 0.0115
Batch [61/14999], Batch Training Loss: 0.0116
Batch [62/14999], Batch Training Loss: 0.0116
Batch [63/14999], Batch Training Loss: 0.0114
Batch [64/14999], Batch Training Loss: 0.0116
Batch [65/14999], Batch Training Loss: 0.0114
Batch [66/14999], Batch Training Loss: 0.0113
Batch [67/14999], Batch Training Loss: 0.0115
Batch [68/14999], Batch Training Loss: 0.0116
Batch [69/14999], Batch Training Loss: 0.0113
Batch [70/14999], Batch Training Loss: 0.0114
Batch [71/14999], Batch Training Loss: 0.0113
Batch [72/14999], Batch Training Loss: 0.0114
Batch [73/14999], Batch Training Loss: 0.0115
Batch [74/14999], Batch Training Loss: 0.0114
Batch [75/14999], Batch Training Loss: 0.0114
Batch [76/14999], Batch Training Loss: 0.0115
Batch [77/14999], Batch Training Loss: 0.0115
Batch [78/14999], Batch Training Loss: 0.0113
Batch [79/14999], Batch Training Loss: 0.0113
Batch [80/14999], Batch Training Loss: 0.0112
Batch [81/14999], Batch Training Loss: 0.0113
Batch [82/14999], Batch Training Loss: 0.0114
Batch [83/14999], Batch Training Loss: 0.0112
Batch [84/14999], Batch Training Loss: 0.0113
Batch [85/14999], Batch Training Loss: 0.0110
Batch [86/14999], Batch Training Loss: 0.0112
Batch [87/14999], Batch Training Loss: 0.0113
Batch [88/14999], Batch Training Loss: 0.0113
Batch [89/14999], Batch Training Loss: 0.0114
Batch [90/14999], Batch Training Loss: 0.0114
Batch [91/14999], Batch Training Loss: 0.0113
Batch [92/14999], Batch Training Loss: 0.0113
Batch [93/14999], Batch Training Loss: 0.0113
Batch [94/14999], Batch Training Loss: 0.0113
Batch [95/14999], Batch Training Loss: 0.0113
Batch [96/14999], Batch Training Loss: 0.0111
Batch [97/14999], Batch Training Loss: 0.0114
Batch [98/14999], Batch Training Loss: 0.0112
Batch [99/14999], Batch Training Loss: 0.0113
Batch [100/14999], Batch Training Loss: 0.0110