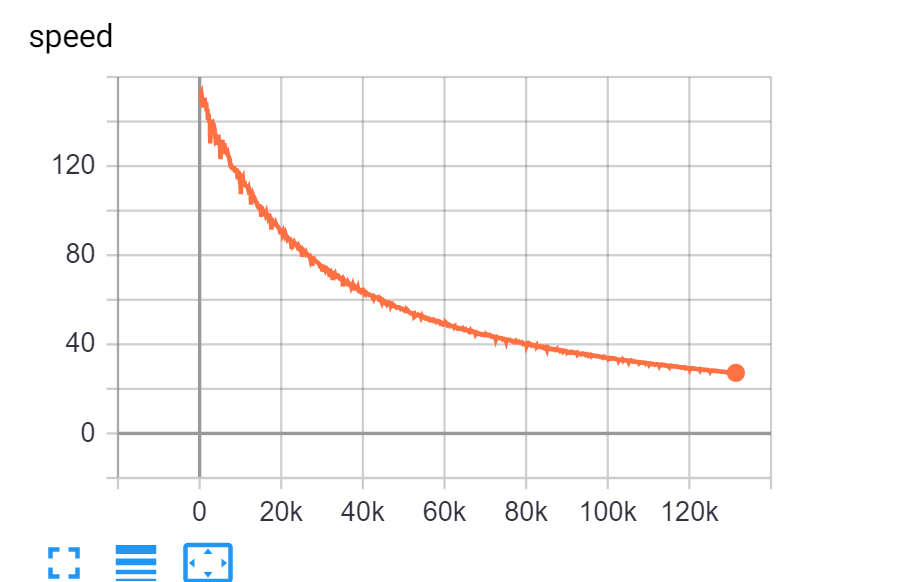
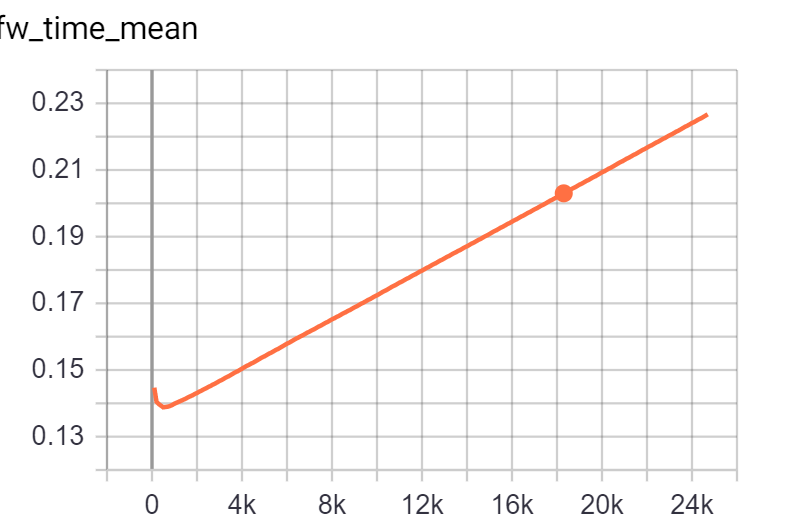
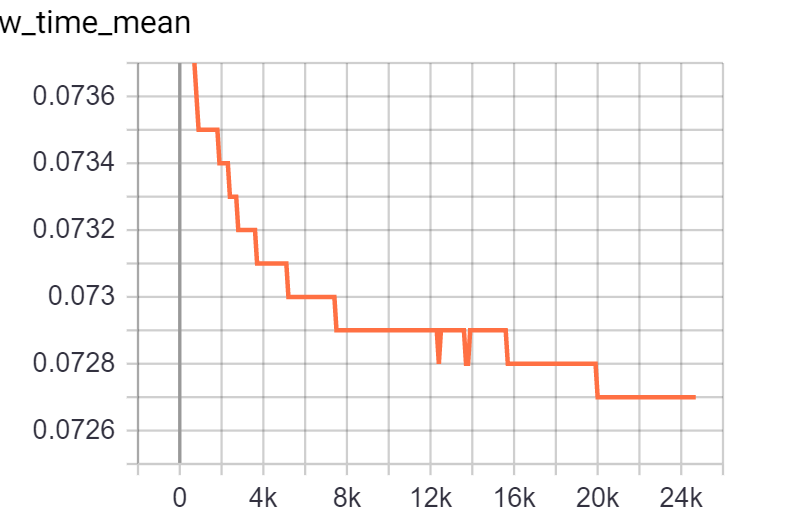
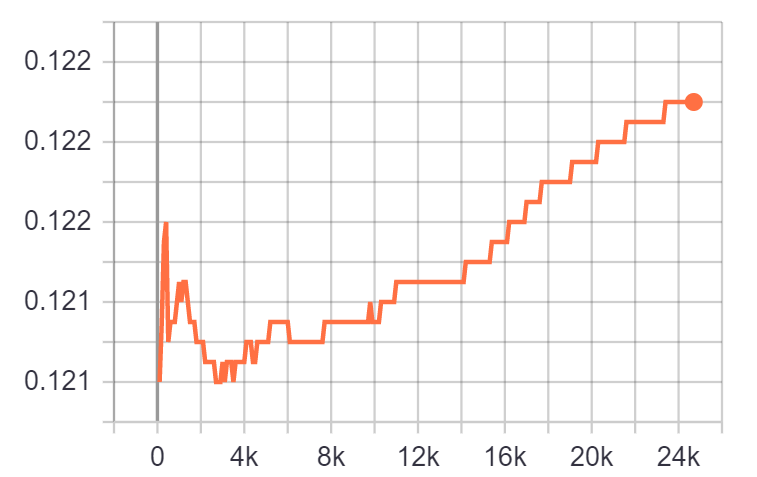
the grad graph size is consistent. The conclusion is drawn by calling the following function (input argument is loss.grad_fn) to see if there is more node added in the graph. The output here is always 11.
def calc_num_node_in_grad_fn(grad_fn):
result = 0
if grad_fn is not None:
result += 1
if hasattr(grad_fn, 'next_functions'):
for f in grad_fn.next_functions:
result += calc_num_node_in_grad_fn(f)
return result
memory cost is not increased. nvidia-smi is called every 30 minutes. The memory size cost is always consistent.
Checked the time cost for forward, backward, parameter update, data loading, and find the time cost of forwarding becomes large. The network is based on efficient-det’s backbone + faster-rcnn. SyncBN is used here. drop-connect is also applied by masking the output as all-0, which should have no dependency on the old iterations.
Is the forward or loss calculation object-dependent, i.e. is the computation increased for each new candidate?
I’m not familiar with your code, but could the model output more candidates, which would have to be filtered out during the forward pass? The backward, update_time, and data loading might be constant + noise.
If you are using the GPU, you would need to synchronize the code before starting and stopping the timer via torch.cuda.synchronize(), since CUDA operations are executed asynchronously.
If you don’t manually synchronize, the next blocking operation will accumulate the timings from the previous ops, so that your results might give you the wrong bottlenecks.