@abadrawy you are using BertForSequenceClassification that is for classifying the sentence into a class like 0,1 or 2. Can you tell me what your final aim is?
Then you should be using BertForQuestionAnswering not BertForSentenceClassification
1 Like
@abadrawy I highly recommend this video for BertForQuestionAnswering https://www.youtube.com/watch?v=l8ZYCvgGu0o
All the best!
1 Like
I’ll check it out, thank you @harsha_g @Kushagra_Bhatia for your time
 All credits to @Kushagra_Bhatia.
All credits to @Kushagra_Bhatia. 
1 Like
But just for the sake of discussion, I got it to work before, using the BertForSequenceClassification, I wanted to treat all the possible words as labels, as if it was, for instance toxic comment classification where each sentence is classified with 5 labels, but in my case it would be classified with 512 labels. I understand that I should use BertForQuestionAnswering, but Couldn’t it work using BertForSequenceClassification as well?
As the name suggests, BertForSequenceClassification is for classifying sequences and not individual tokens. Let us talk about it for a bit. I think what you wanted to do was to get a probability distribution over all the 512 tokens like in Toxic Comment Classification.
You are provided with a large number of Wikipedia comments which have been labeled by human raters for toxic behavior. The types of toxicity are:
toxicsevere_toxicobscenethreatinsultidentity_hateYou must create a model which predicts a probability of each type of toxicity for each comment.
So, the answer to this is yes you can use BertForSequenceClassification. Let us have a look at its implementation.
class BertForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.bert = BertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
@add_start_docstrings_to_callable(BERT_INPUTS_DOCSTRING.format("(batch_size, sequence_length)"))
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`, defaults to :obj:`None`):
Labels for computing the sequence classification/regression loss.
Indices should be in :obj:`[0, ..., config.num_labels - 1]`.
If :obj:`config.num_labels == 1` a regression loss is computed (Mean-Square loss),
If :obj:`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
Returns:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.BertConfig`) and inputs:
loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when :obj:`label` is provided):
Classification (or regression if config.num_labels==1) loss.
logits (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, config.num_labels)`):
Classification (or regression if config.num_labels==1) scores (before SoftMax).
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
outputs = (logits,) + outputs[2:] # add hidden states and attention if they are here
if labels is not None:
if self.num_labels == 1:
# We are doing regression
loss_fct = MSELoss()
loss = loss_fct(logits.view(-1), labels.view(-1))
else:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
outputs = (loss,) + outputs
return outputs # (loss), logits, (hidden_states), (attentions)
As you can see in forward() the pooled_output is fed to an nn.Linear layer. And we get the logits which will be a tensor of shape number of classes. So, if there are 512 classes/labels, the output will be a 512 sized tensor. To get the probabilities we simply have to use a softmax over the logits. However, it must be noted here that it expects a single number (label) for each sequence as the output label for training. For instance each sentence from the Toxic Comment Classification will be having an actual class label for training like toxic–>0, severe toxic–>1, and so on.
In your case, it is suggested to use BertForQuestionAnswering as the answer is a part of the context. So, you are giving [CLS] Question [SEP] Context [SEP] as an input and the answer is a span inside the Context, hence in this case rather than using the pooled output we prefer to use the sequence_outputs which is a more intuitive choice in the case of span answer selection from a context. The following image from the video I had referred to best illustrates BertForQuestionAnswering.
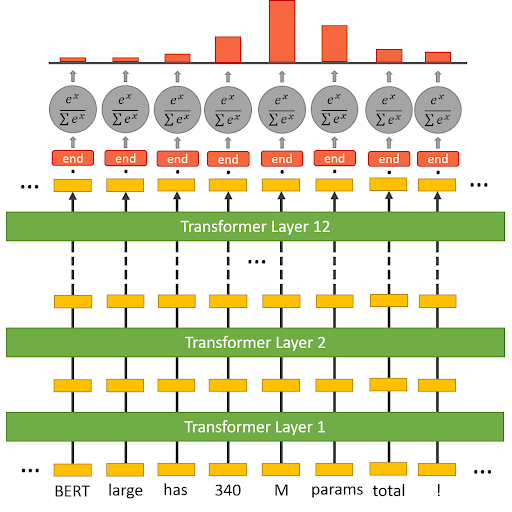
Here, each token in the context gets a probability of being the starting index. And a similar architecture with different weights is used to get the probabilities of being the ending index for the answer span.
1 Like
Thank you for your clear explanation, but what if I don’t have a context. I mean my dataset consists of question and answer pairs. And given an input question (without passing context) I want to infer the right answer. Can I still do this with bert?
On reviewing your notebook, I observed something. You have given pair[0] and pair[1] as input_ids to BERT and you want the labels to be pair[1]. However, if you want to predict something then you are not supposed to give that as input.
sentences = ["[CLS] " + pair[0] + " [SEP] " +pair[1]+" [SEP]" for pair in sentences_orig]
labels=[pair[1] for pair in sentences_orig]
Now coming to your question. If your dataset consists of questions and answers pairs without a context then I believe it can be thought of as an Open-context Question-Answering problem. Effectively you will have to assume a large text corpus as your context (for example all articles on Wikipedia). Rather than giving all the articles use an Information Retrieval module to filter out certain paragraphs more relevant to the question than others. Then use these paragraphs as context like: [CLS] Question [SEP] Paragraph [SEP] input to BERT. Now there are two possibilities the paragraph contains the answer or it doesn’t. If it contains, do the same as earlier for both the start index and end index. In case it doesn’t contain the answer use the pooled output from BERT to classify the question-paragraph pair as non-answerable.