I have been getting the shape error, and I am not sure where the problem is. I have tried reshaping and it still does not work. Any help would greatly be appreciated. The batch size is 1 and the target labels are 512.
Here is the error log
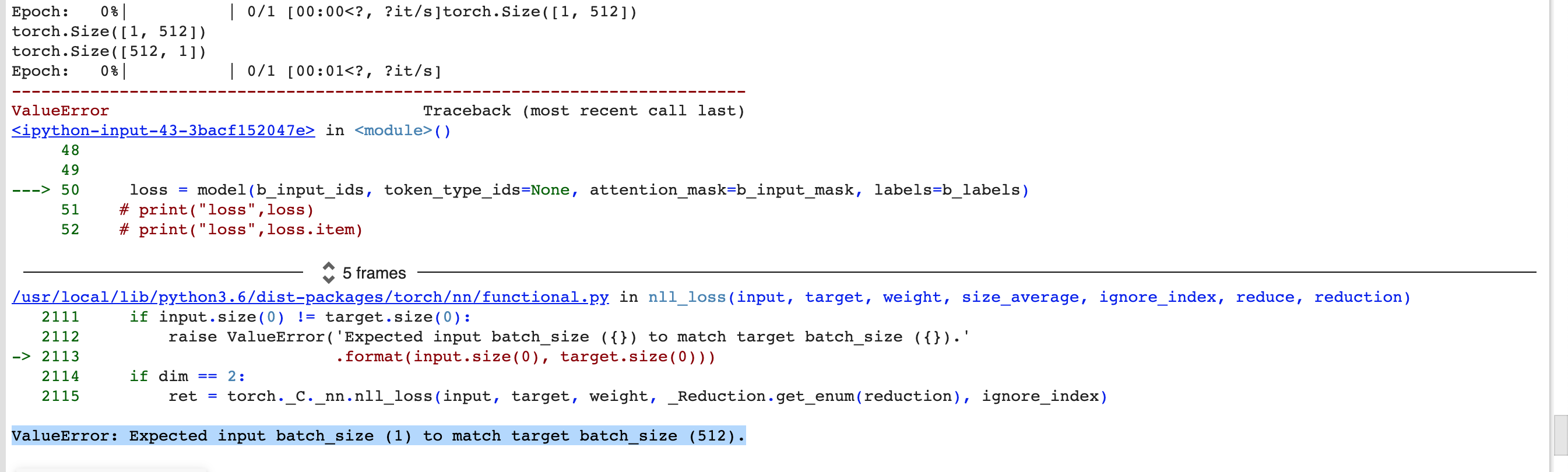
Here us the training code.
t = []
# Store our loss and accuracy for plotting
train_loss_set = []
# Number of training epochs (authors recommend between 2 and 4)
epochs = 1
# trange is a tqdm wrapper around the normal python range
for _ in trange(epochs, desc="Epoch"):
# Training
# Set our model to training mode (as opposed to evaluation mode)
model.train()
# Tracking variables
tr_loss = 0
nb_tr_examples, nb_tr_steps = 0, 0
# Train the data for one epoch
for step, batch in enumerate(train_dataloader):
# Add batch to GPU
batch = tuple(t.to(device) for t in batch)
# Unpack the inputs from our dataloader
b_input_ids, b_input_mask, b_labels = batch
# Clear out the gradients (by default they accumulate)
optimizer.zero_grad()
# Forward pass
#b_input_ids=b_input_ids.resize(MAX_LEN,batch_size)
#b_input_mask=b_input_mask.resize(MAX_LEN,batch_size)
#b_labels=b_labels.resize(batch_size,MAX_LEN)
b_labels = b_labels.view(MAX_LEN,batch_size)
print(b_input_ids.shape)
print(b_input_mask.shape)
print(b_labels.shape)
loss = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask, labels=b_labels)
# print("loss",loss)
# print("loss",loss.item)
train_loss_set.append(loss.item())
# Backward pass
loss.backward()
# Update parameters and take a step using the computed gradient
optimizer.step()
# Update tracking variables
tr_loss += loss.item()
nb_tr_examples += b_input_ids.size(0)
nb_tr_steps += 1
print("Train loss: {}".format(tr_loss/nb_tr_steps))
# Validation
# Put model in evaluation mode to evaluate loss on the validation set
model.eval()
# Tracking variables
eval_loss, eval_accuracy = 0, 0
nb_eval_steps, nb_eval_examples = 0, 0
# Evaluate data for one epoch
for batch in validation_dataloader:
# Add batch to GPU
batch = tuple(t.to(device) for t in batch)
# Unpack the inputs from our dataloader
b_input_ids, b_input_mask, b_labels = batch
# Telling the model not to compute or store gradients, saving memory and speeding up validation
b_labels = b_labels.view(MAX_LEN,batch_size)
print(b_input_ids.shape)
print(b_input_mask.shape)
print(b_labels.shape)
#b_input_ids=b_input_ids.resize(MAX_LEN,batch_size)
#b_input_mask=b_input_mask.resize(MAX_LEN,batch_size)
#b_labels=b_labels.resize(batch_size,MAX_LEN)
with torch.no_grad():
# Forward pass, calculate logit predictions
logits = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)
# Move logits and labels to CPU
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
tmp_eval_accuracy = flat_accuracy(logits, label_ids)
eval_accuracy += tmp_eval_accuracy
nb_eval_steps += 1
print("Validation Accuracy: {}".format(eval_accuracy/nb_eval_steps))```