I’m trying to train a network model on Macbook M1 pro GPU by using the MPS device, but for some reason the training doesn’t converge, and the final training loss is 10x higher on MPS than when training on CPU.
Does anyone have any idea on what could cause this?
def train():
device = torch.device('mps')
epoch_number = 0
EPOCHS = 5
best_vloss = 1_000_000.
model = ESFuturesPricePredictorModel(maps_multiplier=1)
model.to(device)
dataset = ESFuturesDataset('data', ['5m'], [130], common_transform=[my_transform, torch_transform])
# Create data loaders for our datasets; shuffle for training, not for validation
training_loader = torch.utils.data.DataLoader(dataset, batch_size=64*4, shuffle=True, num_workers=4)
#validation_loader = torch.utils.data.DataLoader(validation_set, batch_size=4, shuffle=False, num_workers=2)
loss_fn = torch.nn.MSELoss()
# Report split sizes
print('Training set has {} instances'.format(len(dataset)))
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0001, betas=(0.9, 0.95))
def train_one_epoch(epoch_index):
running_loss = 0.
last_loss = 0.
for i, data in enumerate(training_loader):
inputs, labels = data
for k in inputs.keys():
inputs[k] = inputs[k].to(device)
for k in labels.keys():
labels[k] = labels[k].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_fn(outputs, labels['5m'])
loss.backward()
# Adjust learning weights
optimizer.step()
# Gather data and report
running_loss += loss.item()
if i % 100 == 99:
last_loss = running_loss / 100 # loss per batch
print(' batch {} loss: {}'.format(i + 1, last_loss))
running_loss = 0.
return last_loss
for epoch in range(EPOCHS):
print('EPOCH {}:'.format(epoch_number + 1))
model.train(True)
avg_loss = train_one_epoch(epoch_number)
print('LOSS train {}'.format(avg_loss))
epoch_number += 1
I have experienced similar things training with MPS. My networks converge using CPU but not when using the MPS device. This is with multiple different versions, most recently:
pytorch 1.13.0.dev20220929 py3.9_0 pytorch-nightly
Same happened to me. On my desktop using Cuda, same training converge but on M1 laptop, it didnt converge. I will try to troubleshoot If I can and share here.
Any solution to this problem yet ? It hasn’t been funny for me for more than 24 hours now. Same model I trained a week ago is no longer converging on M1 GPU but works on CPU.
I’m facing the same issue here, running torch 2.2.0 on M2.
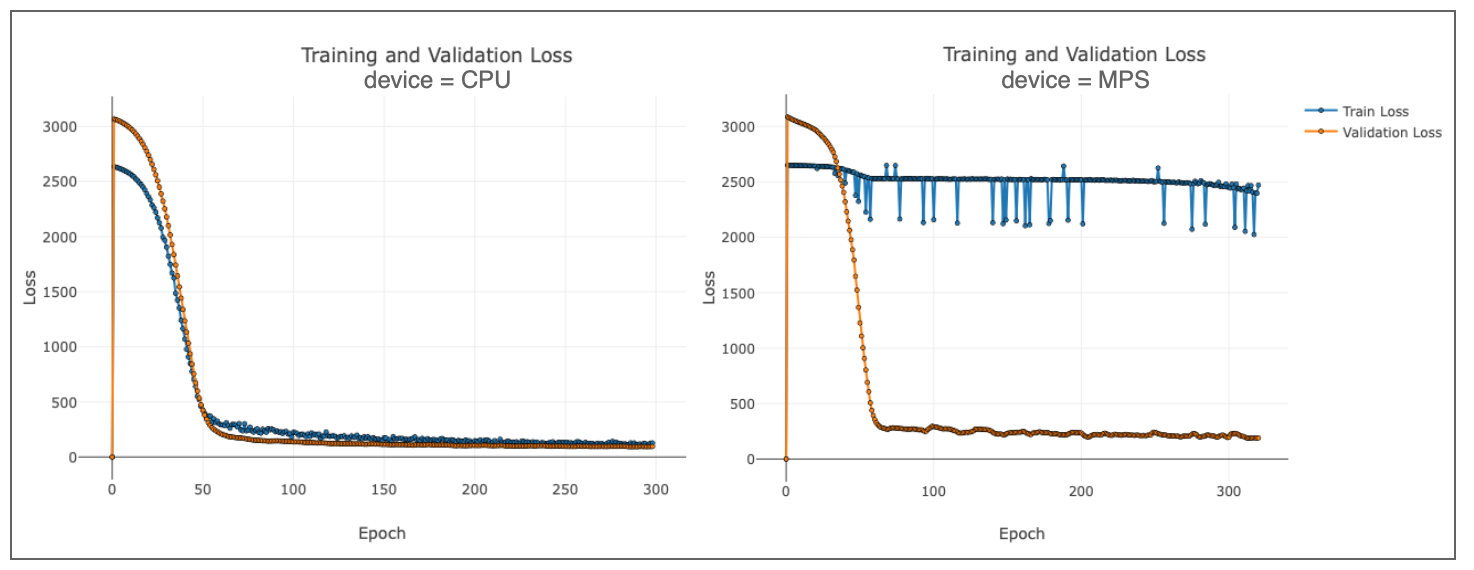
In the figure, we can observe the loss throughout the first epochs (~350) using the exact same parameters to train the same model. This result is systematic; regardless of the parameters or architecture, performance on the CPU consistently outperforms that on MPS.
I had a similar problem, not sure if this is related. My problem was, that copying the tensors from cpu to mps didn’t really do a copy (even it had to, according to the docs). So the tensors got corrupted getting the next batch asynchronously. Forcing a copy with “copy=True” fixed that.