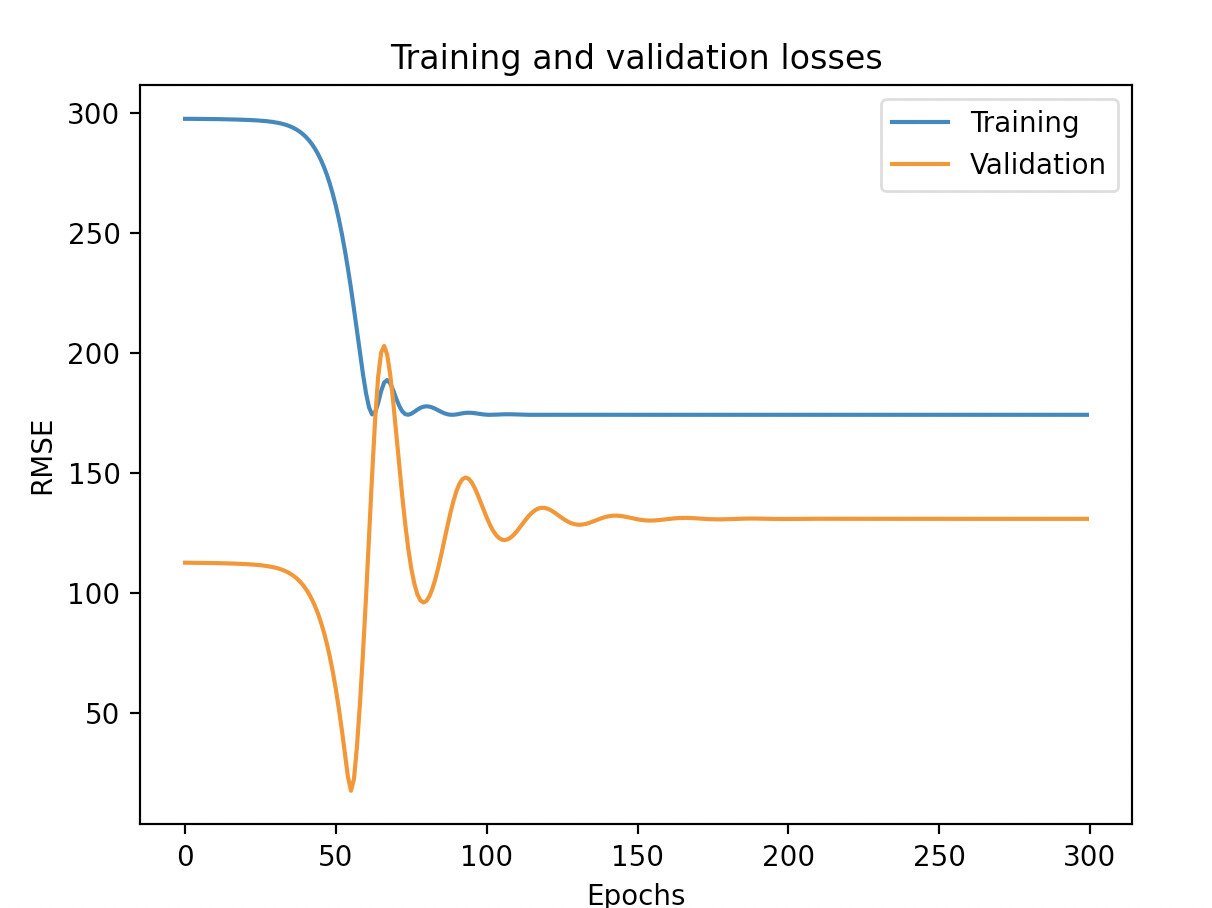
Hi everyone,
Here’s my problem. I have a basic 1D-CNN trained for regression purposes (my training data are spectra of length 543).
I do not have errors when training (input shape seems in the right format [N_obs, Channel, Width]), but there is definitely a problem with my model since it cannot overfit even on few data (5 in this example - 4 in training 1 in test) and my training loss curve looks weird (it decreases very quicky then reach a plateau and stays there ad vitam aeternam).
I think I need an external point of view to see if there is someting wrong in my code. Thank you for you help.
Here’s my complete code.
My main function:
num_epochs = 300
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
X_train, X_test, y_train, y_test = train_test_split(
X_train, y_train, train_size=0.8)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# output: (4, 543) (1, 543) (4,) (1,)
train_data = TabularDataset(X_train, y_train)
test_data = TabularDataset(X_test, y_test)
model = ConvNet_1D()
optimizer = Adam(model.parameters(), lr=0.001)
train_dataloader = DataLoader(train_data, batch_size=128, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=128, shuffle=True)
for X, y in test_dataloader:
print("Shape of X: ", X.shape, X.dtype)
# Output: Shape of X: torch.Size([1, 1, 543]) torch.float64
print("Shape of y: ", y.shape, y.dtype)
break
# # Model training
losses_x: list = []
losses_y: list = []
for epoch in range(0, num_epochs):
print(f"Epoch {epoch + 1}\n----------------------------")
loss_x = training_function(train_dataloader, model, optimizer, device)
loss_y = testing_function(test_dataloader, model, device)
losses_x.append(loss_x)
losses_y.append(loss_y)
My CNN architecture:
from torch import nn
class ConvNet_1D(nn.Module):
'''
Defines a 1D-CNN architecture with batch normalization and max pooling layers.
'''
def __init__(self, dropout=0):
super(ConvNet_1D, self).__init__()
self.ConvNet = nn.Sequential(
nn.Conv1d(in_channels=1, out_channels=32, kernel_size=3),
nn.ReLU(),
nn.BatchNorm1d(32),
nn.MaxPool1d(kernel_size=2),
nn.Conv1d(in_channels=32, out_channels=64, kernel_size=3),
nn.ReLU(),
nn.BatchNorm1d(64),
nn.MaxPool1d(kernel_size=2),
nn.Conv1d(in_channels=64, out_channels=128, kernel_size=3),
nn.ReLU(),
nn.BatchNorm1d(128),
nn.MaxPool1d(kernel_size=2),
nn.Conv1d(in_channels=128, out_channels=256, kernel_size=3),
nn.ReLU(),
nn.BatchNorm1d(256),
nn.MaxPool1d(kernel_size=2),
nn.Dropout(dropout),
nn.Flatten(),
)
self.task = nn.Sequential(
nn.Linear(8192, 100),
nn.Dropout(dropout),
nn.ReLU(),
nn.Linear(100, 1),
)
def forward(self, x):
x = self.ConvNet(x)
output = self.task(x)
return output
My dataloader:
import numpy as np
import torch
from torch.utils.data import Dataset
class TabularDataset(Dataset):
def __init__(self, train, labels, transform=None):
self.train = train
self.labels = labels
self.transform = transform
def __len__(self):
return len(self.labels)
def get_data(self):
return self.train
def __getitem__(self, idx):
x = torch.tensor(self.train[idx]).unsqueeze(0)
y = torch.tensor(self.labels[idx])
# Apply various transformations to your data here
if self.transform:
x, y = self.transform(x), self.transform(y)
return x, y
My training function:
import torch
from xxx.utils import RMSELoss
def training_function(dataloader, model, optimizer, device, scheduler=None):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# Compute the prediction error
pred = model(X.float())
loss = RMSELoss(pred, y)
# Reset the gradient to 0 after each epoch
optimizer.zero_grad()
# Compute the backpropagation (back propagate the loss and add one step to the optimizer)
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss = loss.item()
print(f"training loss: {loss:>7f}")
return loss
def testing_function(dataloader, model, device):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
# set the gradient to 0 (since we do not need to calculate the gradient on the test set)
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X.float())
test_loss += RMSELoss(pred, y).item()
correct += (pred == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Validation loss: {test_loss:>8f} \n")
return test_loss