I trained LSTM-MDN model using Adam, the training loss decreased firstly, but after serveral hundreds epoch, it increased and higher than Initial value. Then I retrained from the point where the loss was lowest and reduced learning rate 10 times(from 1e-3 to 1e-4). The training loss alse decreased firstly and increased later.I initially thought there was some bugs in the code, but I didn’t find any bug. Then I replaced adam with SGD(momentum=0), training loss didn’t increased, but it converged to a relatively large value which was higher than the loss from adam, so I thougtht there was something wrong in adam.
I never found the reason, I hope someone can help me find the reason.Thansk!
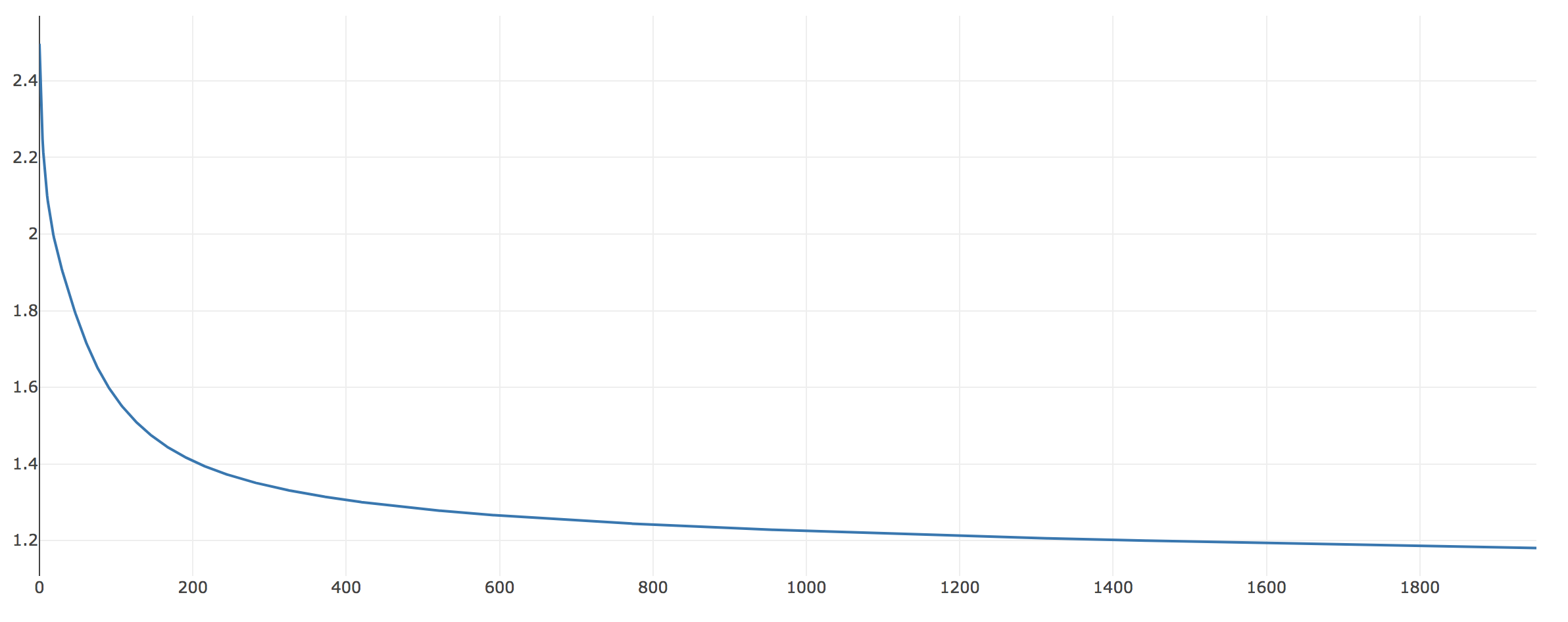
loss (adam)

1 Like

Do you zero out the gradients after each optimizer step?
I’ve seen similar behavior when the gradients were accidentally accumulated.
1 Like
I really appreciate you replying to me.Here is my code.Is there a wrong order between computing the loss and calling zero_grad? Thank you very much~~

1 Like
When I replaced adam with SGD(momentum=0), training loss didn’t increase, but it converged to a relatively large value which was higher than the loss from adam.
The order of your calls looks alright.
I’m unfortunately not really familiar with your use case and the loss function you are using.
Also, what is ensure_shared_grad doing? Is it just copying the current gradients to another model?
Yes, it is. Thanks for your replying.I’m still looking for the reason.Maybe there is something wrong with adam?
I also encounter this issue.
Is there any suggestion when we use adam optimizer?
I had a similar issue. The problem was that I was training with mixed precision bf16, which caused numerical instability with the Adam optimizer.
I switched to fp32 for backward, and everything worked well.