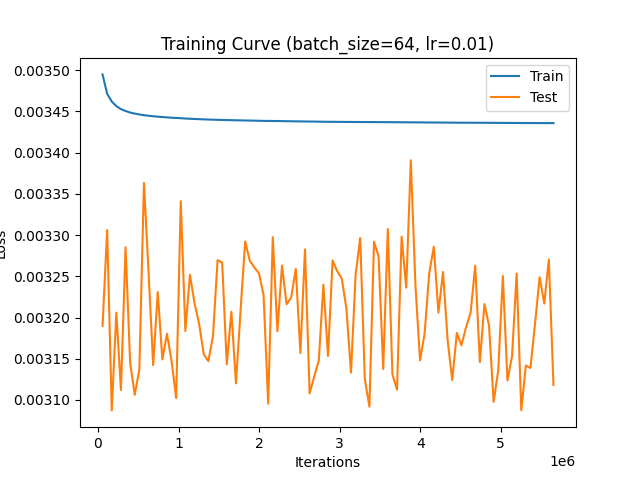
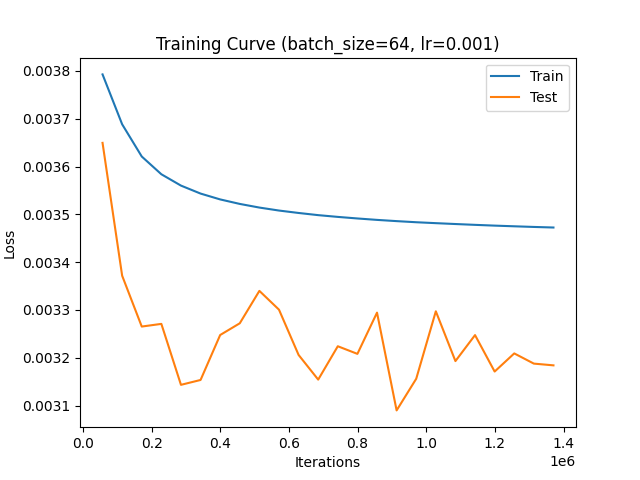
I am training PyTorch model for binary classification and my input vector of length 561 [341 is one hot encoding] and the others are features between 0 and 1. my output is [0,1] or [1,0] . My issue is that the training loss is always decrease i tried to try more epochs until 200 but nothing change, I am wondering if I am calculating the loss in wrong way, sometimes training loss is decreasing and test loss is decrease and increase.
Here is my model, I also tried different models with lstm and cnn and the loss always decreasing
class MyRegression(nn.Module):
def __init__(self, input_dim, output_dim):
super(MyRegression, self).__init__()
# One layer
self.linear1 = nn.Linear(input_dim, 128)
self.linear2 = nn.Linear(128, output_dim)
def forward(self, x):
return self.linear2(self.linear1(x))
and the training function
def run_gradient_descent(model, data_train, data_val, batch_size, learning_rate, weight_decay=0, num_epochs=20):
model = model.to(device)
criterion = nn.CrossEntropyLoss()
#criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
iters, losses, train_losses, test_losses = [], [], [], []
iters_sub, train_acc, val_acc = [], [] ,[]
print(batch_size)
# weight sampler
class0, class1 =labels_count(data_train)
dataset_counts = [class0, class1]
print(dataset_counts)
num_samples = sum(dataset_counts)
labels = [tag for _, tag in data_train]
#max_value = max(input_list)
#index = input_list.index(max_value)
class_weights = [1./dataset_counts[i] for i in range(len(dataset_counts))]
labels_indics = [i.index(max(i)) for i in labels ]
weights = [class_weights[i] for i in labels_indics] # labels.max(1, keepdim=True)[1]
weights = numpy.array(weights)
samples_weight = torch.from_numpy(weights)
samples_weigth = samples_weight.double()
sampler = torch.utils.data.sampler.WeightedRandomSampler(samples_weight, int(num_samples), replacement=True)
train_loader = torch.utils.data.DataLoader(
data_train,
batch_size=batch_size,
shuffle=False,
sampler = sampler,
collate_fn=lambda d: ([x[0] for x in d], [x[1] for x in d]),
num_workers=os.cpu_count()//2
)
# training
n = 0 # the number of iterations
for epoch in tqdm(range(num_epochs), desc="epoch"):
correct = 0
total = 0
for xs, ts in tqdm(train_loader, desc="train"):
xs = torch.FloatTensor(xs).to(device)
ts = torch.FloatTensor(ts).to(device)
# print("batch index {}, 0/1: {}/{}".format(n,ts.tolist().count([1,0]),ts.tolist().count([0,1])))
# if len(ts) != batch_size:
# print("ops")
# continue
model.train()
zs = model(xs)
zs = zs.to(device)
loss = criterion(zs, ts)
loss.backward()
optimizer.step()
optimizer.zero_grad()
iters.append(n)
loss.detach().cpu()
losses.append(float(loss)/len(ts)) # compute *average* loss
pred = zs.max(1, keepdim=True)[1] # get the index of the max logit
target = ts.max(1, keepdim=True)[1]
correct += pred.eq(target).sum().item()
total += int(ts.shape[0])
acc = correct / total
if (n % len(train_loader) == 0) and n>0 and epoch%2==0:
test_acc, test_loss = get_accuracy(model, data_val)
iters_sub.append(n)
train_acc.append(acc)
val_acc.append(test_acc)
train_losses.append(sum(losses)/len(losses))
test_losses.append(test_loss)
print("Epoch", epoch, "train_acc", acc)
print("Epoch", epoch, "test_acc", test_acc)
print("Epoch", epoch, "train_loss", sum(losses)/len(losses))
print("Epoch", epoch, "test_loss", test_loss)
# increment the iteration number
n += 1
torch.save(model.state_dict(), f"{MODEL_NAME}/checkpoint_epoch{epoch}.pt")
# plotting
plt.title("Training Curve (batch_size={}, lr={})".format(batch_size, learning_rate))
plt.plot(iters_sub, train_losses, label="Train")
plt.plot(iters_sub, test_losses, label="Test")
plt.legend(loc='best')
plt.xlabel("Iterations")
plt.ylabel("Loss")
plt.savefig(f"{MODEL_NAME}/training_test_loss.png")
# plt.show()
plt.clf()
plt.title("Training Curve (batch_size={}, lr={})".format(batch_size, learning_rate))
plt.plot(iters_sub, train_acc, label="Train")
plt.plot(iters_sub, val_acc, label="Test")
plt.xlabel("Iterations")
plt.ylabel("Accuracy")
plt.legend(loc='best')
plt.savefig(f"{MODEL_NAME}/training_acc.png")
#plt.show()
return model
main function
model = MyRegression(374, 2)
run_gradient_descent(
model,
training_set,
test_set,
batch_size= 64,
learning_rate=1e-2,
num_epochs=200
)
Here is part of the training results so you can see that is is decreasing
Epoch 2 train_acc 0.578125
Epoch 2 test_acc 0.7346171218510883
Epoch 2 train_loss 0.003494985813946325
Epoch 2 test_loss 0.00318981208993754
Epoch 4 train_acc 0.671875
Epoch 4 test_acc 0.7021743310868525
Epoch 4 train_loss 0.0034714722261212196
Epoch 4 test_loss 0.0033061892530283398
Epoch 6 train_acc 0.75
Epoch 6 test_acc 0.7614966302787455
Epoch 6 train_loss 0.003462064279302097
Epoch 6 test_loss 0.003087314312623757
Epoch 8 train_acc 0.625
Epoch 8 test_acc 0.7343577405202831
Epoch 8 train_loss 0.0034565126970269753
Epoch 8 test_loss 0.0032059013449951632
Epoch 10 train_acc 0.578125
Epoch 10 test_acc 0.7587194612023667
Epoch 10 train_loss 0.0034528369772701857
Epoch 10 test_loss 0.003112017690331294
Epoch 12 train_acc 0.65625
Epoch 12 test_acc 0.7097187501397528
Epoch 12 train_loss 0.003450584381555143
Epoch 12 test_loss 0.003285413007535127
Epoch 14 train_acc 0.578125
Epoch 14 test_acc 0.7509648538296759
Epoch 14 train_loss 0.0034486886994226553
Epoch 14 test_loss 0.003145160475069196
Epoch 16 train_acc 0.625
Epoch 16 test_acc 0.7629612403794123
Epoch 16 train_loss 0.0034474354597715125
Epoch 16 test_loss 0.003106232365138448
Epoch 18 train_acc 0.703125
Epoch 18 test_acc 0.7527134417666552
Epoch 18 train_loss 0.0034464063646294537
Epoch 18 test_loss 0.0031368749897371824
Epoch 20 train_acc 0.734375
Epoch 20 test_acc 0.6917431767057677
Epoch 20 train_loss 0.0034454527557537763
Epoch 20 test_loss 0.003363367490148118
Epoch 22 train_acc 0.671875
Epoch 22 test_acc 0.7229382538269926
Epoch 22 train_loss 0.003444858143091548
Epoch 22 test_loss 0.003254974437443727
Epoch 24 train_acc 0.703125
Epoch 24 test_acc 0.7514299513883609
Epoch 24 train_loss 0.003444201508544531
Epoch 24 test_loss 0.0031422660971916283