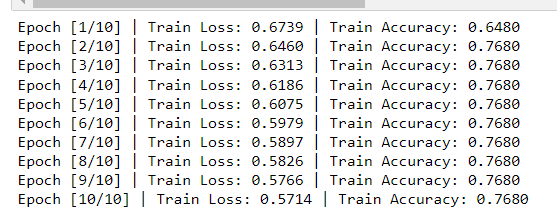
I tried both the approach but the accuracy is still staying constant at 0.7680.
Shape of my dataset:
X_train shape is:
torch.Size([65802, 4, 250, 1])
Y_train shape is:
torch.Size([65802, 1, 1])
X_val shape is:
torch.Size([16920, 4, 250, 1])
Y_val shape is:
torch.Size([16920, 1])
X_test shape is:
torch.Size([11281, 4, 250, 1])
Y_test shape is:
torch.Size([11281, 1])
Mycode:
x_train, x_val, y_train, y_val = train_test_split(features, labels, test_size=0.3, random_state=42)
x_val, x_test, y_val, y_test = train_test_split(x_val, y_val, test_size=0.4, random_state=42)
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
import torch.nn.functional as F
class CustomDataset(Dataset):
def __init__(self, features, labels):
self.features = []
for feature in features:
if len(feature) >= 2:
self.features.append(feature)
self.labels = labels
def __len__(self):
return len(self.features)
def __getitem__(self, index):
return self.features[index], self.labels[index]
class RelationAwareFeatureExtractor(nn.Module):
def __init__(self):
super(RelationAwareFeatureExtractor, self).__init__()
# ConvNet layers
self.conv1 = nn.Conv2d(4, 16, kernel_size=3, stride=2, padding=1)
self.pool1 = nn.MaxPool2d(kernel_size=1, stride=1)
self.conv2 = nn.Conv2d(16, 64, kernel_size=3, stride=2, padding=1)
self.pool2 = nn.MaxPool2d(kernel_size=1, stride=1)
self.conv3 = nn.Conv2d(64, 125, kernel_size=3, stride=2, padding=1)
self.fc1 = nn.Linear(125*8*4, 1024)
self.fc2 = nn.Linear(1024, 128)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.pool1(x)
x = F.relu(self.conv2(x))
x = self.pool2(x)
x = F.relu(self.conv3(x))
# Flatten the tensor before fully connected layers
x = torch.flatten(x, start_dim=1) # Flatten dimensions except batch dimension
# Fully connected layers
x = self.fc1(x)
x = self.fc2(x)
return x
class SelfAttention(nn.Module):
def __init__(self, hidden_size):
super(SelfAttention, self).__init__()
self.W = nn.Linear(hidden_size,hidden_size)
def forward(self, x):
batch_size, seq_len = x.size()
x = self.W(x)
x = F.relu(x)
return x
class ConditionalRandomFields(nn.Module):
def __init__(self, hidden_size):
super(ConditionalRandomFields, self).__init__()
self.crf = nn.Linear(hidden_size, 2)
def forward(self, x):
x = self.crf(x)
return x
class AnomalyDetector(nn.Module):
def __init__(self):
super(AnomalyDetector, self).__init__()
# Feature extractor
self.feature_extractor = RelationAwareFeatureExtractor()
# Self-attention layer
self.self_attention = SelfAttention(128)
# Conditional random fields layer
self.conditional_random_fields = ConditionalRandomFields(128)
def forward(self, x):
# Extract features
x = self.feature_extractor(x)
x = self.self_attention(x)
log_likelihood = self.conditional_random_fields(x)
return log_likelihood
input_dim = 125
hidden_dim = 50
output_dim = 124
# Define the train and test datasets
train_dataset = CustomDataset(x_train[:1000], y_train[:1000])
val_dataset = CustomDataset(x_val[:300], y_val[:300])
test_dataset = CustomDataset(x_test[:100], y_test[:100])
# Define the train loader
batch_size = 4
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# Create an instance of the AnomalyDetector
model = AnomalyDetector()
# Define the loss function (negative log-likelihood)
criterion = nn.NLLLoss()
# Define the optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)