Hi all, I’m training a neural network with both CNN and RNN, but I found that although the training loss is consistently decreasing, the validation loss remains as NaN.
Here is an example:
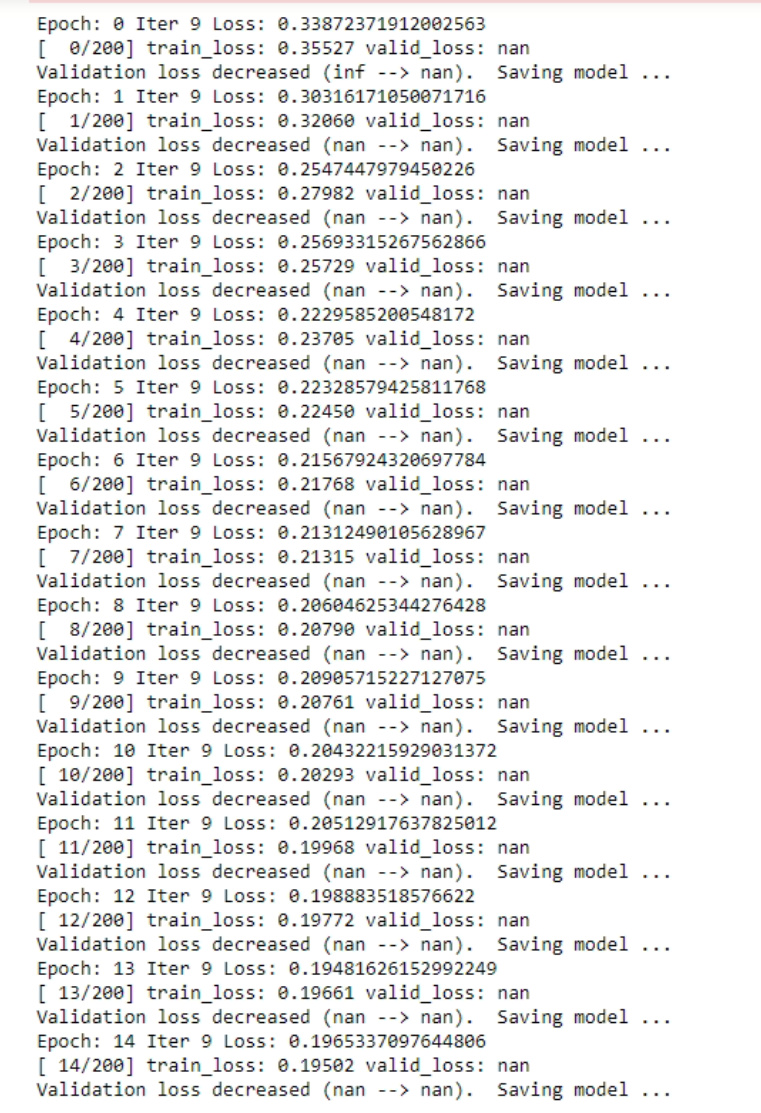
Any idea why?
>
> models = [model1, model2, model3]
> for epoch in range(epochs):
> [model.train() for model in models]
> for i, (data, label) in enumerate(dataloader_train):
> data = Variable(data).cuda().float()
> label = torch.squeeze(label)
> label = Variable(label).cuda().float()
> # CNN + RNN
> batch_size, timesteps, C, H, W = data.size()
> c_in = data.view(batch_size * timesteps, C, H, W)
> c_out = model1(c_in)
> _, C, H, W = c_out.size()
> c_out = c_out.view(batch_size, timesteps, C, H, W)
> r_out = model2(c_out)
> pred = model3(r_out)
> pred = torch.sigmoid(pred)
> # training loss update
> loss = criterion(pred, label)
> optimizer.zero_grad()
> loss.backward()
> optimizer.step()
> train_losses.append(loss.item())
> if (i + 1) % 10 == 0:
> print('Epoch:', epoch, 'Iter', i, 'Loss:', loss.item())
> [model.eval() for model in models]
> with torch.no_grad():
> for i, (data, label) in enumerate(dataloader_valid):
> data = Variable(data).cuda().float()
> label = torch.squeeze(label)
> label = Variable(label).cuda().float()
> # CNN + RNN
> batch_size, timesteps, C, H, W = data.size()
> c_in = data.view(batch_size * timesteps, C, H, W)
> c_out = model1(c_in)
> _, C, H, W = c_out.size()
> c_out = c_out.view(batch_size, timesteps, C, H, W)
> r_out = model2(c_out)
> pred = model3(r_out)
> pred = torch.sigmoid(pred)
> # validation loss update
> loss = criterion(pred, label)
> valid_losses.append(loss.item())
Here is a snippet of training and validation, I’m using a combined CNN+RNN network, model 1,2,3 are encoder, RNN, decoder respectively.
