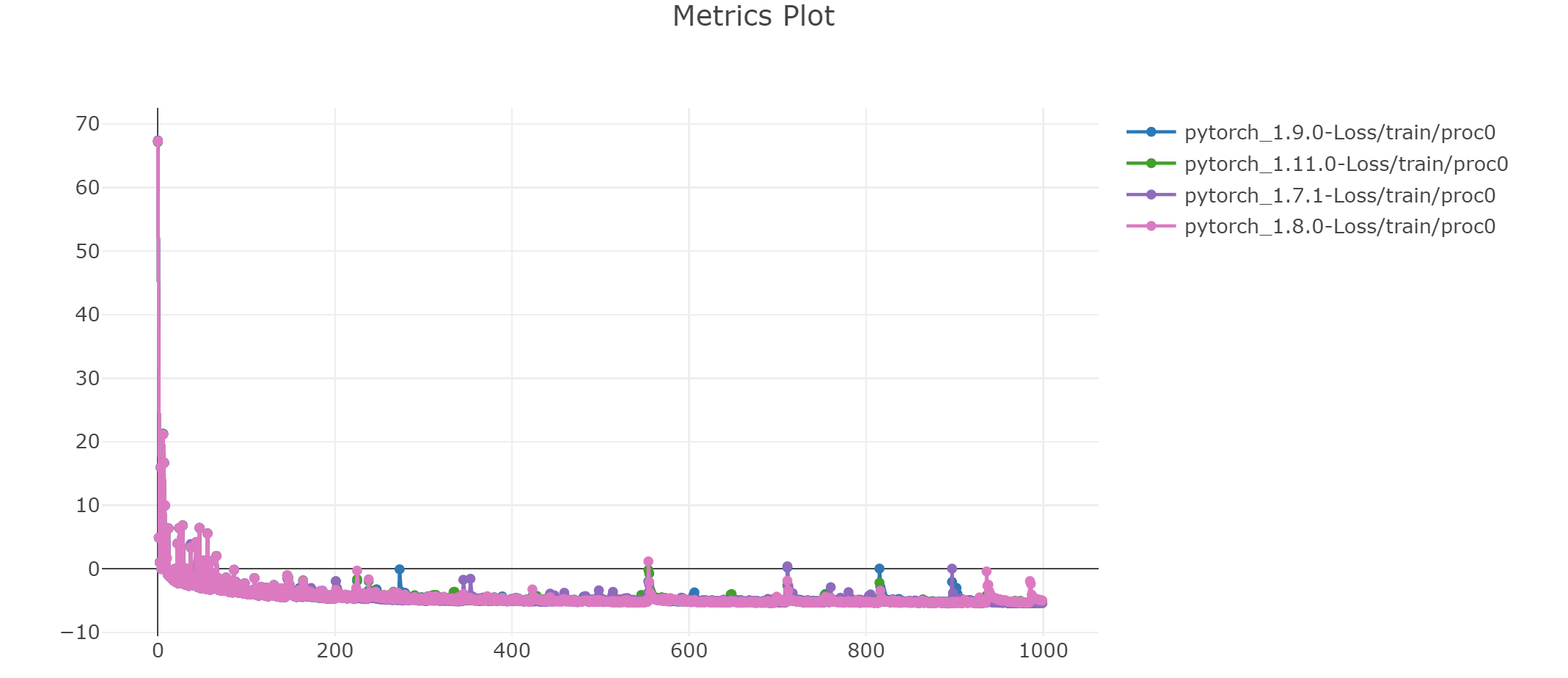
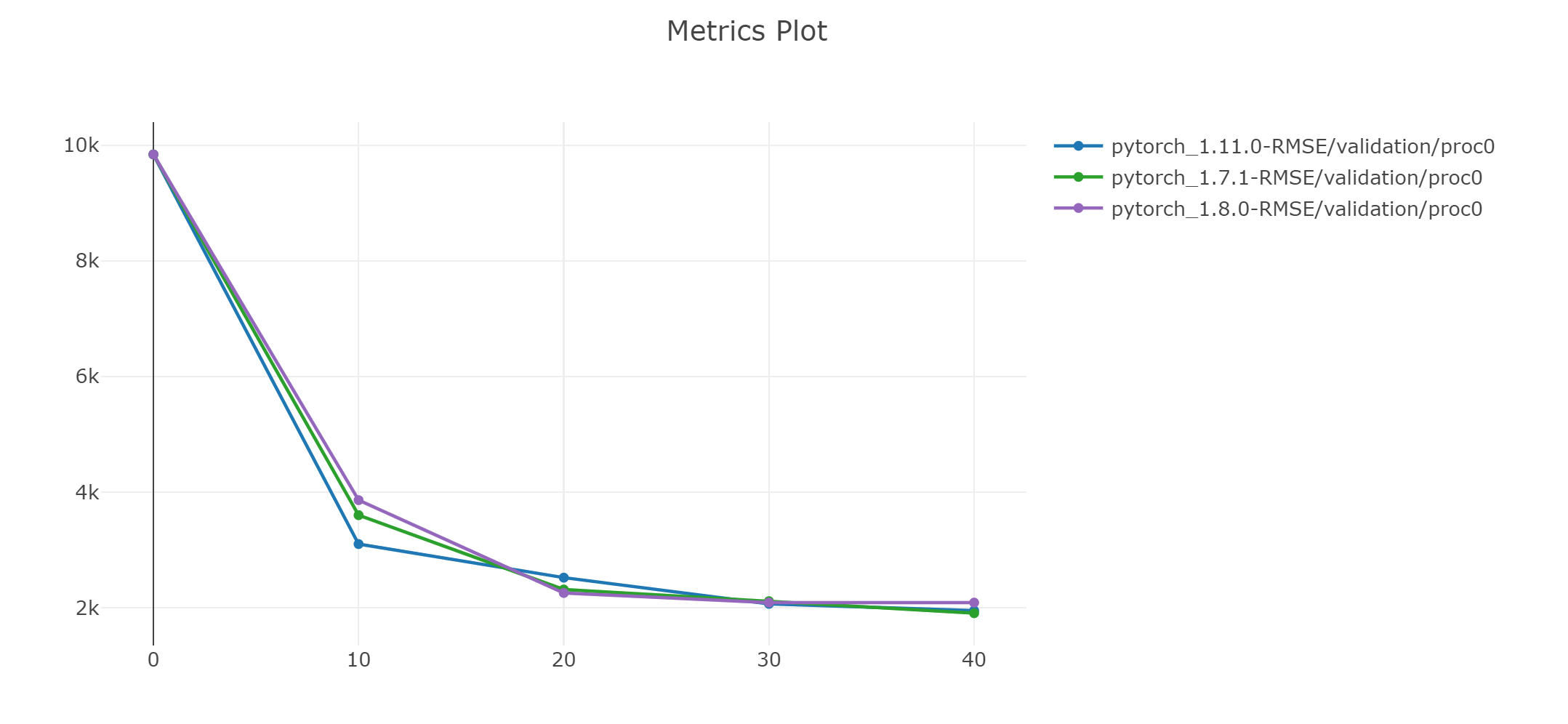
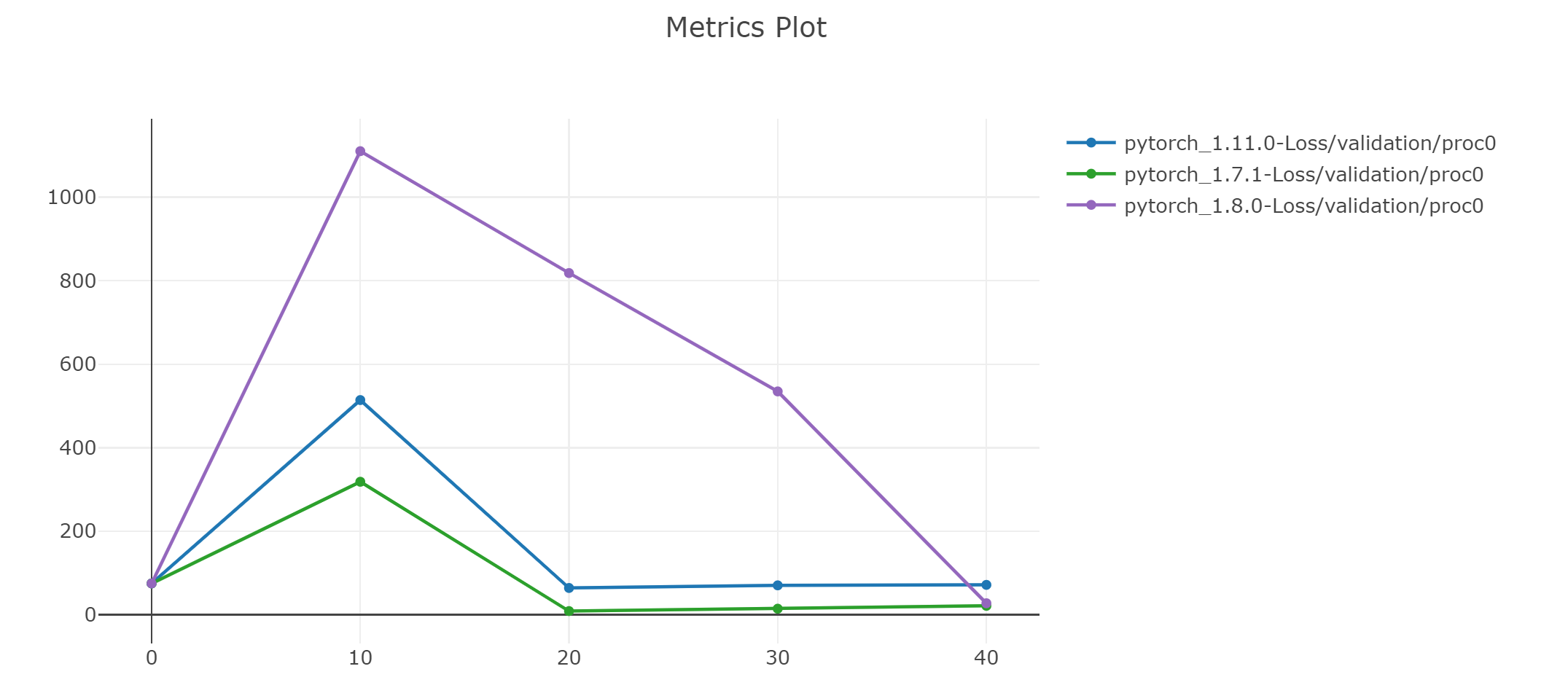
Hi, I am not sure what your network architecture is but in my opinion, maybe if you are not using any weight initialization for your layers then from version to version there may be other basic weights in layers. Also some other functions can be improved.
I used xavier_uniform, xavier_normal in custom attention layer and reset_parameter function in pre-defined pytorch layers e.g: nn.Linear, nn.LayerNorm, nn.Dropout.
Your answer is related to reset_parameter function in torch layers.
Thanks to reply my question. I try it!
Also if some guys have a solution or advise, then please reply your answer!
Completely reproducible results are not guaranteed across PyTorch releases, individual commits, or different platforms. Furthermore, results may not be reproducible between CPU and GPU executions, even when using identical seeds.
There are numerous factors affecting reproducibility.
What about the quantitative results in terms of accuracy?
You haven’t talked about it. Can you pl. share if they are more or less equal?
Your saying is that if I train models in same machine environment (like same CPU and GPU), then completely reproducible results are not guaranteed across PyTorch releases?