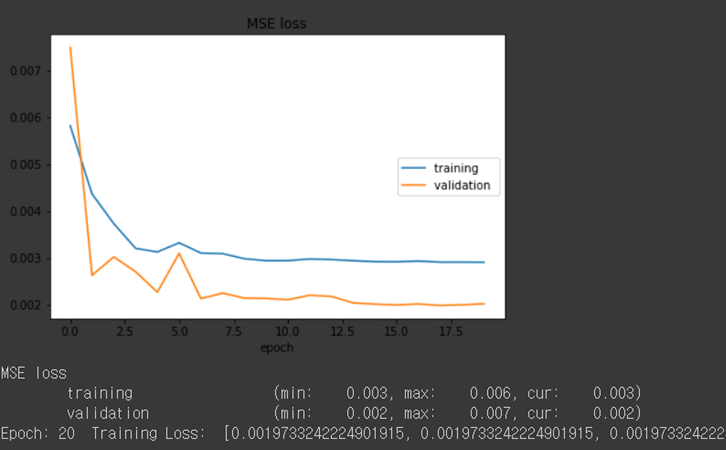
Hi. My model is autoencoder. In the training phase, I draw plot points in every epoch. but I think training loss should be less then validation loss. but no matter what hyperparameter I use, training loss is greater.
Is it underfitting? or Is it okay?
my code here:
from livelossplot import PlotLosses
def train(model, patch_train_loader, patch_val_loader, EPOCHS):
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=1e-5)
liveloss = PlotLosses()
lr2_tr_loss = []
lr2_val_loss = []
for epoch in range(EPOCHS):
model_losses, valid_losses = [], []
running_loss = 0.0
logs = {}
prefix = ''
model.train()
# with train data
for idx, (data,target) in enumerate(patch_train_loader):
data = torch.autograd.Variable(data).to(device = device, dtype = torch.float)
optimizer.zero_grad()
pred = model(data)
loss = loss_func(pred, data)
# Backpropagation
loss.backward()
# update
optimizer.step()
model_losses.append(loss.cpu().data.item())
logs[prefix + 'MSE loss'] = loss.item()
model_losses.append(loss.cpu().data.item())
running_loss += loss.item()
model_losses.append(loss.item())
print(idx,"complete")
## with validation data(only nodefect)
with torch.no_grad():
for idx, (data,target) in enumerate(patch_val_loader):
model.eval()
data = torch.autograd.Variable(data).to(device = device, dtype = torch.float)
pred = model(data)
loss = loss_func(pred, data)
valid_losses.append(loss.item())
prefix = 'val_'
logs[prefix + 'MSE loss'] = loss.item()
lr2_tr_loss.append(np.mean(model_losses))
lr2_val_loss.append(np.mean(valid_losses))
liveloss.update(logs)
liveloss.draw()
print ("Epoch:", epoch+1, " Training Loss: ", np.mean(model_losses), " Valid Loss: ", np.mean(valid_losses))
if epoch == EPOCHS -1:
torch.save(model.state_dict(), path)
return lr2_tr_loss, lr2_val_loss
Thank you.