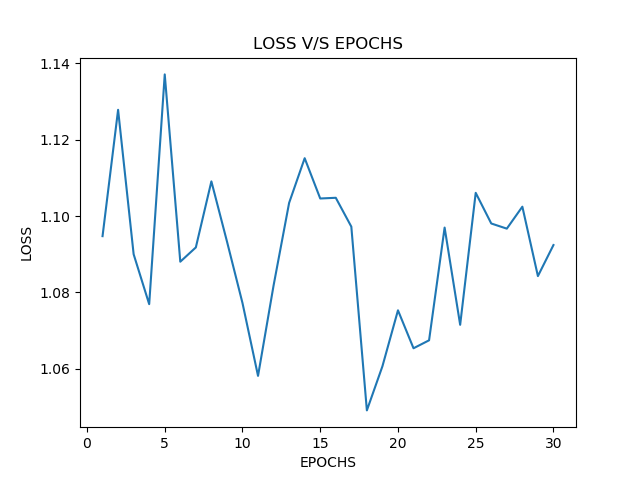
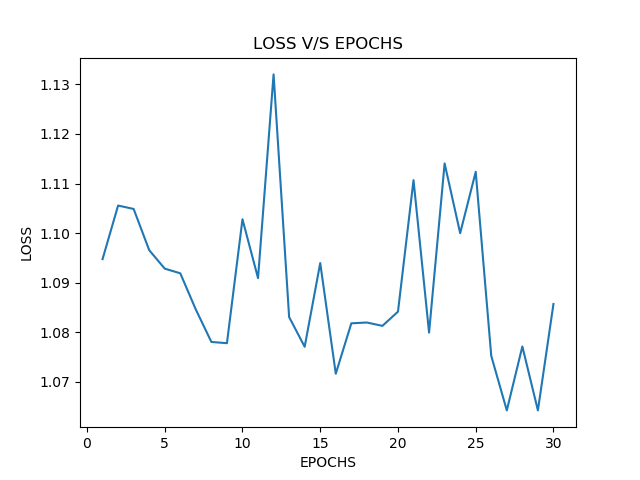
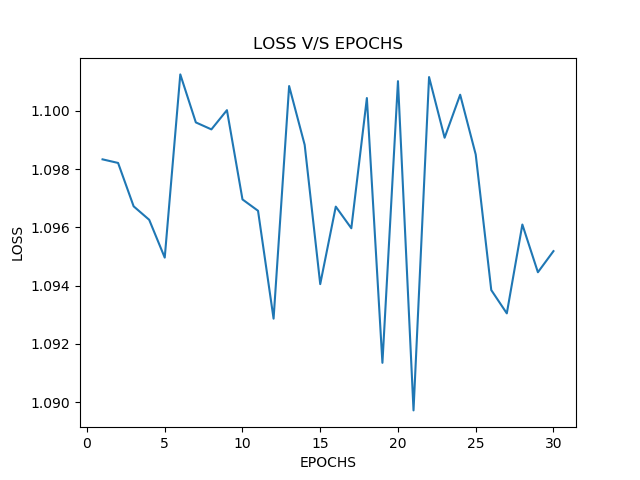
I am trying to solve a text classification problem. My training data has input as a sequence of 80 numbers in which each represent a word and target value is just a number between 1 and 3.
I pass it through this model:
class Model(nn.Module):
def __init__(self, tokenize_vocab_count):
super().__init__()
self.embd = nn.Embedding(tokenize_vocab_count+1, 300)
self.embd_dropout = nn.Dropout(0.3)
self.LSTM = nn.LSTM(input_size=300, hidden_size=100, dropout=0.3, batch_first=True)
self.lin1 = nn.Linear(100, 1024)
self.lin2 = nn.Linear(1024, 512)
self.lin_dropout = nn.Dropout(0.8)
self.lin3 = nn.Linear(512, 3)
def forward(self, inp):
inp = self.embd_dropout(self.embd(inp))
inp, (h_t, h_o) = self.LSTM(inp)
h_t = F.relu(self.lin_dropout(self.lin1(h_t)))
h_t = F.relu(self.lin_dropout(self.lin2(h_t)))
out = F.softmax(self.lin3(h_t))
return out
My training loop is as follows:
model = Model(tokenizer_obj.count+1).to('cuda')
optimizer = optim.AdamW(model.parameters(), lr=1e-2)
loss_fn = nn.CrossEntropyLoss()
EPOCH = 10
for epoch in range(0, EPOCH):
for feature, target in tqdm(author_dataloader):
train_loss = loss_fn(model(feature.to('cuda')).view(-1, 3), target.to('cuda'))
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
print(f"epoch: {epoch + 1}\tTrain Loss : {train_loss}")
I printed out the feature and target dimension and it is as follows:
torch.Size([64, 80]) torch.Size([64])
Here 64 is the batch_size.
I am not doing any validation as of now.
When I train I am getting a constant loss value and no change
/home/koushik/Software/miniconda3/envs/fastai/lib/python3.7/site-packages/torch/nn/modules/rnn.py:50: UserWarning: dropout option adds dropout after all but last recurrent layer, so non-zero dropout expects num_layers greater than 1, but got dropout=0.3 and num_layers=1
"num_layers={}".format(dropout, num_layers))
0%| | 0/306 [00:00<?, ?it/s]/media/koushik/Backup Plus/Code/Machine Deep Learning/NLP/src/Deep Learning/model.py:20: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
out = F.softmax(self.lin3(h_t))
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 306/306 [00:03<00:00, 89.36it/s]
epoch: 1 Train Loss : 1.0986120700836182
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 306/306 [00:03<00:00, 89.97it/s]
epoch: 2 Train Loss : 1.0986120700836182
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 306/306 [00:03<00:00, 89.35it/s]
epoch: 3 Train Loss : 1.0986120700836182
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 306/306 [00:03<00:00, 89.17it/s]
epoch: 4 Train Loss : 1.0986120700836182
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 306/306 [00:03<00:00, 88.72it/s]
epoch: 5 Train Loss : 1.0986120700836182
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 306/306 [00:03<00:00, 87.75it/s]
epoch: 6 Train Loss : 1.0986120700836182
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 306/306 [00:03<00:00, 85.67it/s]
epoch: 7 Train Loss : 1.0986120700836182
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 306/306 [00:03<00:00, 85.40it/s]
epoch: 8 Train Loss : 1.0986120700836182
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 306/306 [00:03<00:00, 84.49it/s]
epoch: 9 Train Loss : 1.0986120700836182
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 306/306 [00:03<00:00, 84.21it/s]
epoch: 10 Train Loss : 1.0986120700836182
Can anyone please help