using a simple DNN to predict Tox21 toxicity.
with following model
class DNN(nn.Module):
def __init__(self, n_features, n_layers, n_classes):
super(DNN, self).__init__()
self.layers = nn.ModuleList()
in_features = n_features
n_hidden = in_features//2
for i in range(n_layers):
self.layers.append(nn.Linear(in_features, n_hidden))
self.layers.append(nn.GELU())
self.layers.append(nn.LayerNorm(n_hidden))
self.layers.append(nn.Dropout(0.5))
in_features = n_hidden
n_hidden = n_hidden // 2
self.layers = nn.Sequential(*self.layers)
self.classifier = nn.Linear(n_hidden *2 , n_classes)
self._init_weights()
def _init_weights(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.kaiming_uniform_(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
x = self.layers(x)
output = self.classifier(x)
return output
model = DNN(n_features=1024, n_layers=3, n_classes=12)
Tune and train
#hyperparameters
batch_size = 128
n_epochs = 3
learning_rate = 1e-5
weight_decay = 1e-6
num_workers = 2
# X_train y_train are numpy arrays.
trainset = TensorDataset(torch.from_numpy(X_train).float(), torch.from_numpy(y_train).float())
testset = TensorDataset(torch.from_numpy(X_train).float(), torch.from_numpy(y_train).float())
trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=num_workers)
testloader = DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=num_workers)
loader = (trainloader, testloader)
def train(model, loader, weight_decay):
model = model.to(device)
train_loader, valid_loader = loader
best_valid = 0.1
optimizer = opt.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
scheduler = CosineAnnealingLR(optimizer, T_max=n_epochs)
criterion = nn.BCEWithLogitsLoss()
Loss = []
Loss_valid = []
# train_scores = []
# valid_scores = []
losses= 0
for epoch in range(n_epochs):
for _,(x, y)in enumerate(train_loader):
# model.train()
x, y = x.to(device), y.to(device)
output = model(x)
mask = torch.where(y < 0, torch.zeros_like(y), torch.ones_like(y))
# mask = (y != -1).float()
# mask out unknowns
output = output * mask
y = y * mask
loss = criterion(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses += loss.item()
# pred = torch.sigmoid(output).detach().cpu().numpy()
# y = y.detach().cpu().numpy()
# try:
# train_scores.append(roc_auc_score(y.ravel(), pred.ravel()))
# except:
# pass
losstrain = losses/len(train_loader)
Loss.append(losstrain)
# Evaluate on validation set
valid,valid_score = evaluate(model, valid_loader, criterion)
Loss_valid.append(valid)
# valid_scores.append(valid_score)
scheduler.step()
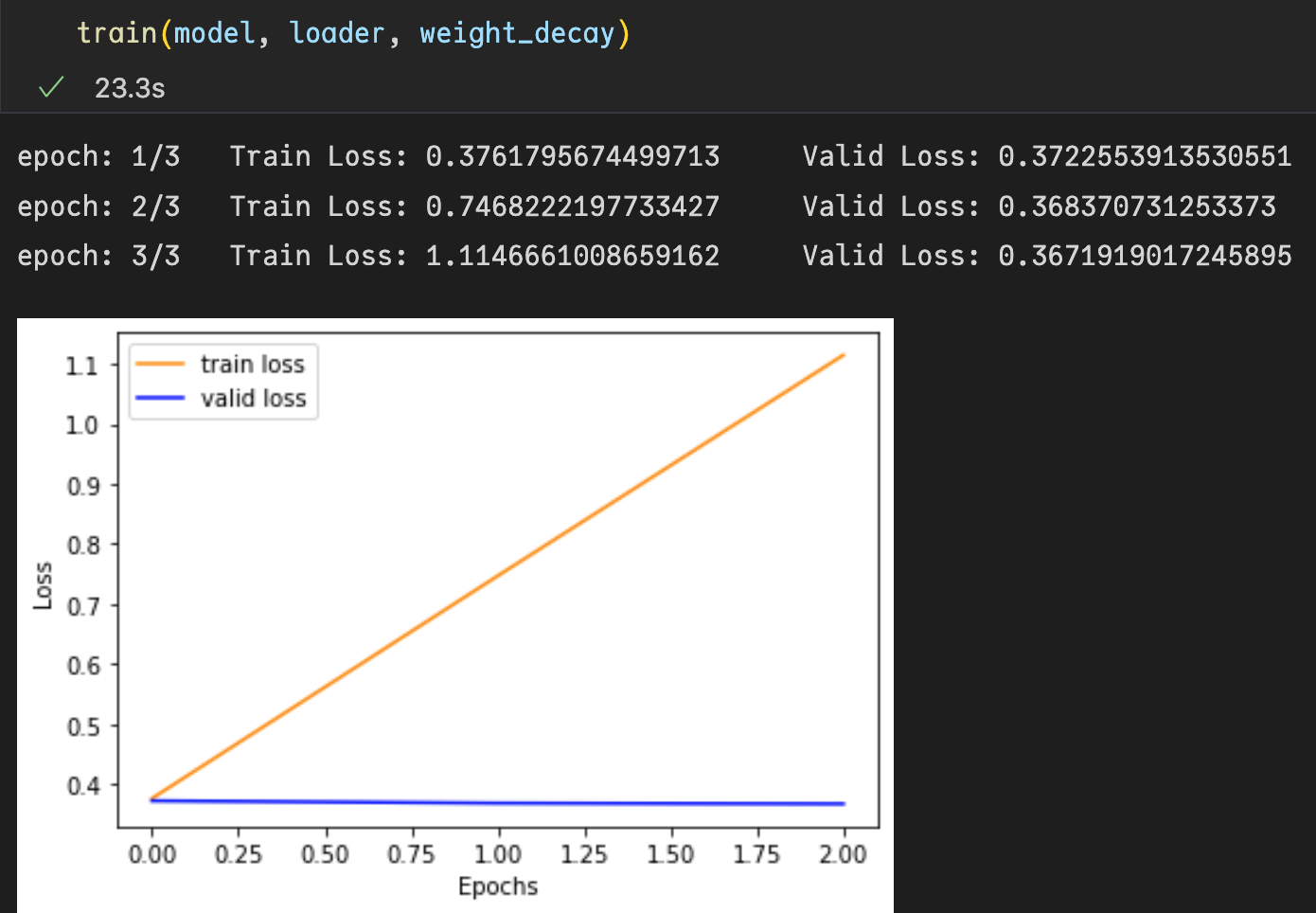
but got the following peculiar results.What could be the problem?