Hey community,
I have hit a brick wall on a project I am working on for my master’s dissertation. The project is to compare different methods used for explainable AI in image recognition ( LIME SHAP and Grad CAM). Before doing that, I need to create a classifier for the images. The problem I am facing is that when training a vgg16 or Alexnet models on the, [Fairface Dataset]
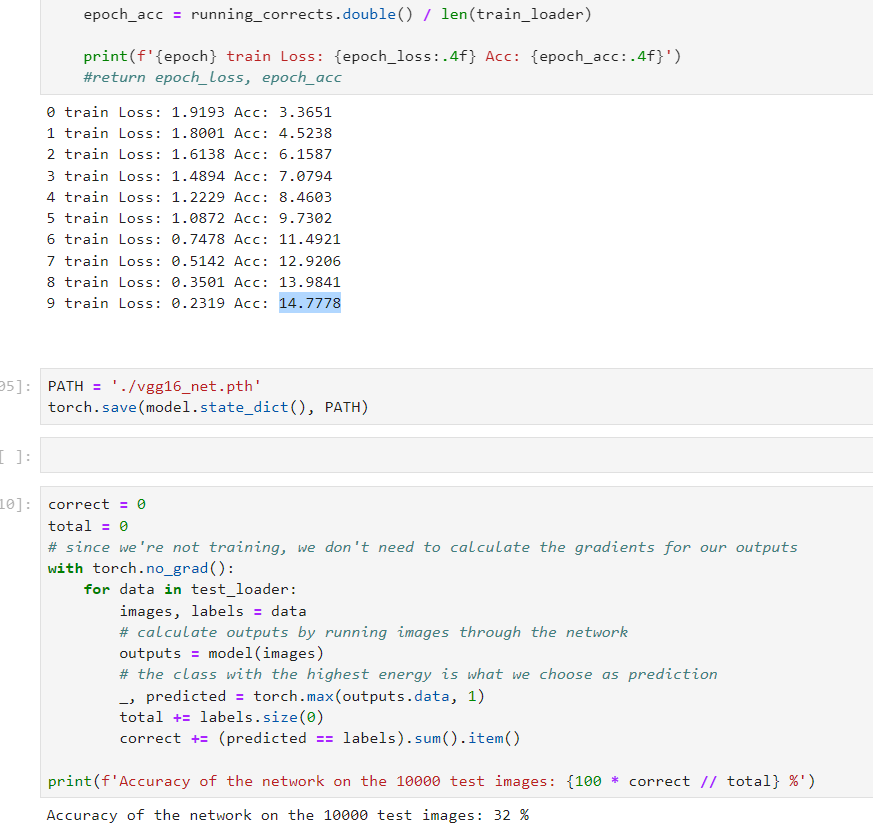
(GitHub - joojs/fairface: FairFace: Face Attribute Dataset for Balanced Race, Gender, and Age), the loss keeps increasing by approx double after each iteration and the training accuracy goes beyond 100 after 5 epoch (148). I am sure something is wrong somewhere but I cant figure out what the problem is and I a kindly asking for assistance.
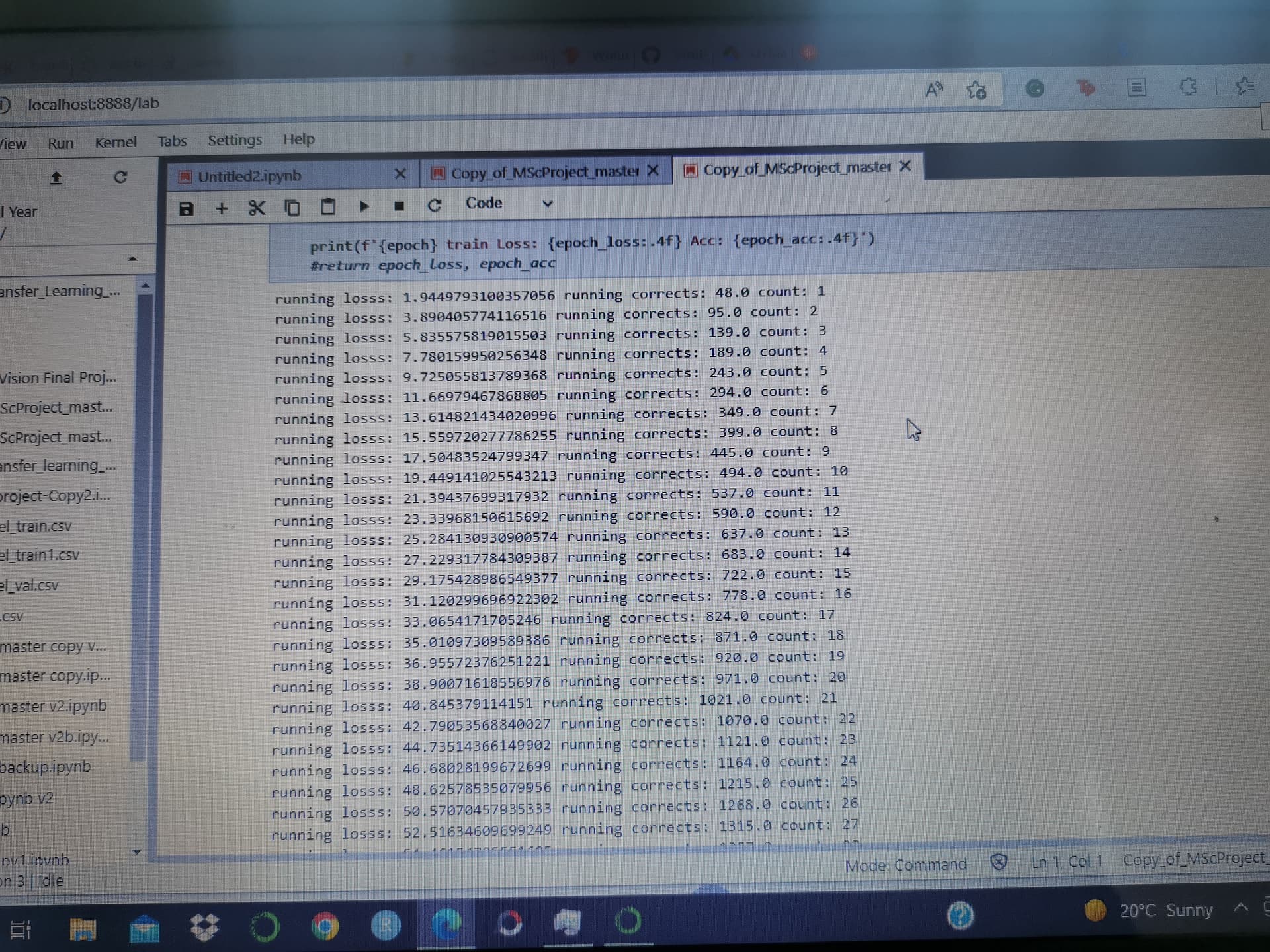
training loss for the first few iterations
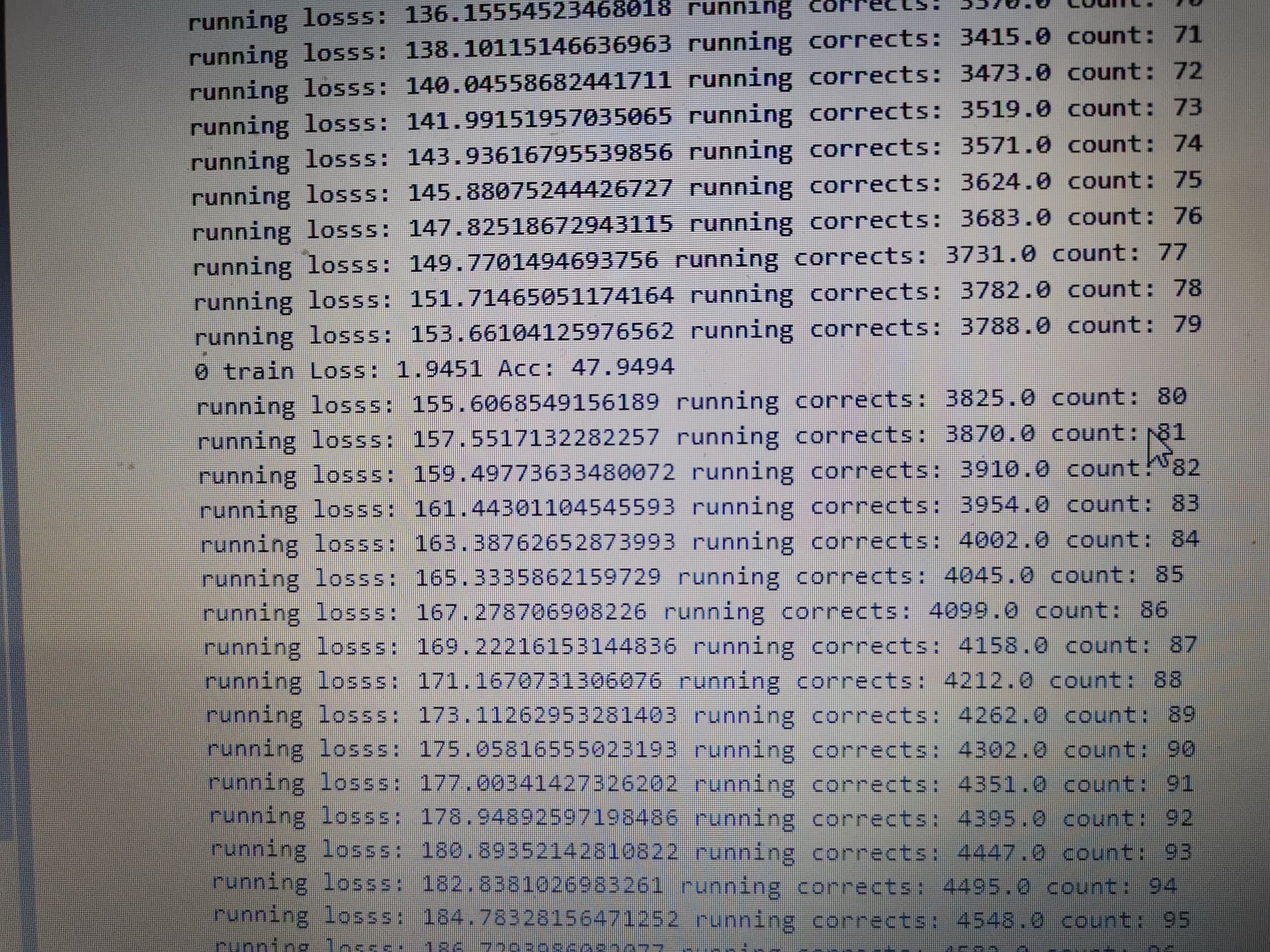
Training loss after the first epoch
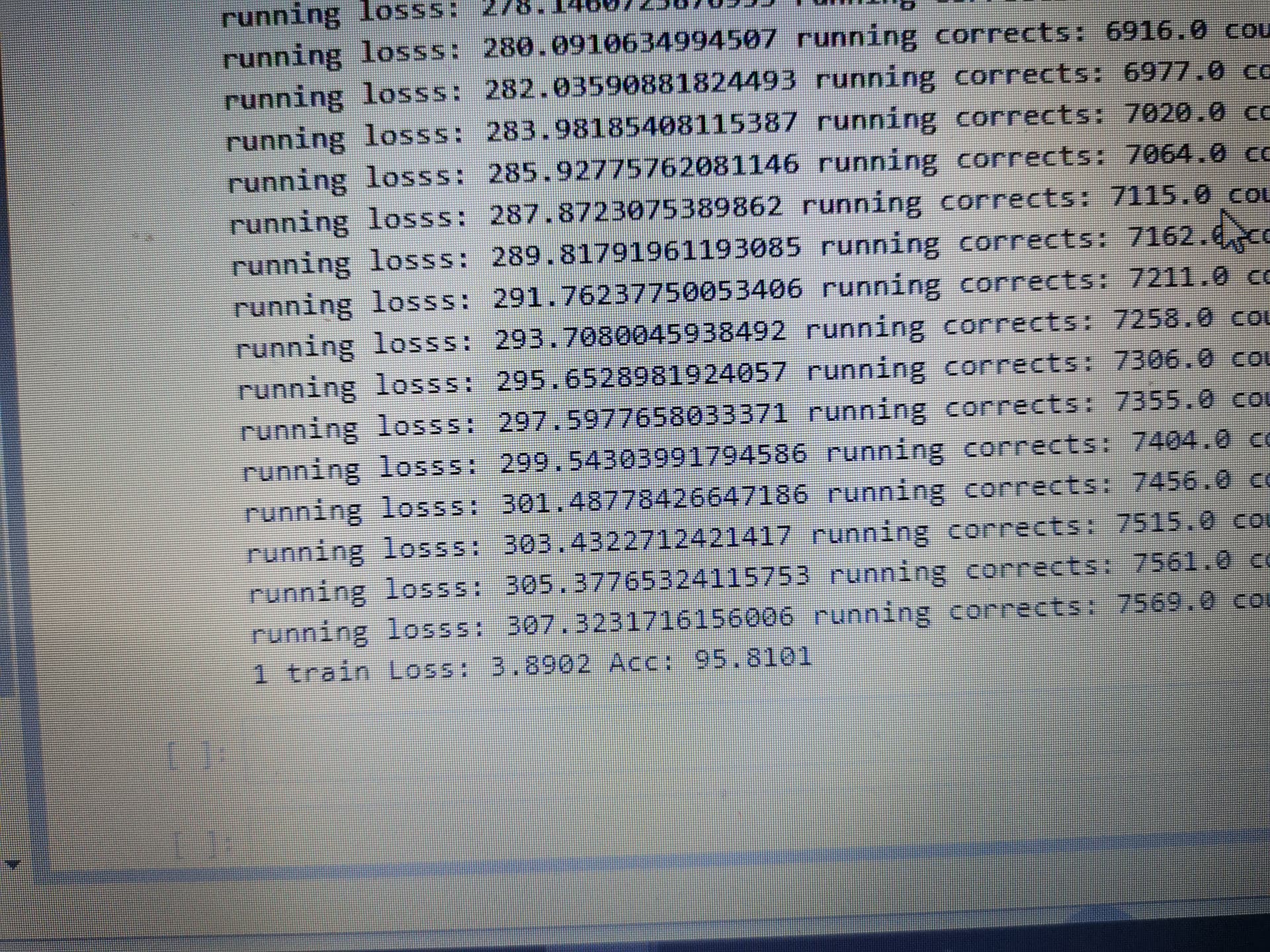
training loss after 2 epochs
below is my code. I have only included the the custom dataset and training code but happy to provide further details.
#custom Dataset class to load the custom data
class CustomDataset(Dataset):
def __init__(self, csv_file, root_dir, transform=None):
self.annotations = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.annotations)
def __getitem__(self, index):
#if torch.is_tensor(index):
#idx = idx.tolist()
img_path = os.path.join(self.root_dir, self.annotations.iloc[index, 0])
image = io.imread(img_path)
#convert str labels to int labels
class_map = {'Latino_Hispanic': 0,
'East Asian': 1,
'Indian': 2,
'Middle Eastern': 3,
'Black': 4,
'Southeast Asian': 5,
'White': 6
}
label = self.annotations.iloc[index, 3] # returns a tuple of strings
label =class_map[label]
#label= OneHotEncoder(label)
#label = label.applylambda label: list(map(int, label)))
if self.transform:
image = self.transform(image)
return image, label
vis_augs = transforms.Compose([
T.ToPILImage(),
T.Resize((224,224)),
T.ToTensor()
]
)
train_data = CustomDataset(
csv_file="fairface_label_train.csv",
root_dir="train/",
transform=vis_augs,
)
# Load Data
test_data = CustomDataset(
csv_file="fairface_label_val.csv",
root_dir="/val",
transform=vis_augs,
)
batch_size =256
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_data,batch_size=batch_size, shuffle=True)
model = model.to(device)
criterion = nn.CrossEntropyLoss()
#Observe that all parameters are being optimized
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
The training loop is as below:
# Put model in train mode
model.train()
running_loss = 0.0
running_corrects =0.0
counter = 0
for epoch in range(2):
# Iterate over data.
for inputs, labels in train_loader:
set_trace()
counter +=1
#inputs, labels =data
inputs = inputs.to(device)
labels = labels.to(device)
#set_trace()
# zero the parameter gradients
optimizer.zero_grad()
# forward
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
# preds = torch.argmax(torch.softmax(pred, dim=1), dim=1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'running losss: {running_loss}', end= " ")
running_corrects += torch.sum(preds == labels)
print(f'running corrects: {running_corrects}', end= " ")
#scheduler.step()
print(f'iteration: {counter}')
epoch_loss = running_loss / len(train_loader)
epoch_acc = running_corrects.double() / len(train_loader)
print(f'{epoch} train Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
#return epoch_loss, epoch_acc