Hi guys, I’m a novice in deep learning. Right now I’m trying to use AE to predict the data, while I found my validation loss is equally same as the training loss, is that make sense? (I have checked the datasets of training and validation, and there is no duplication in them)
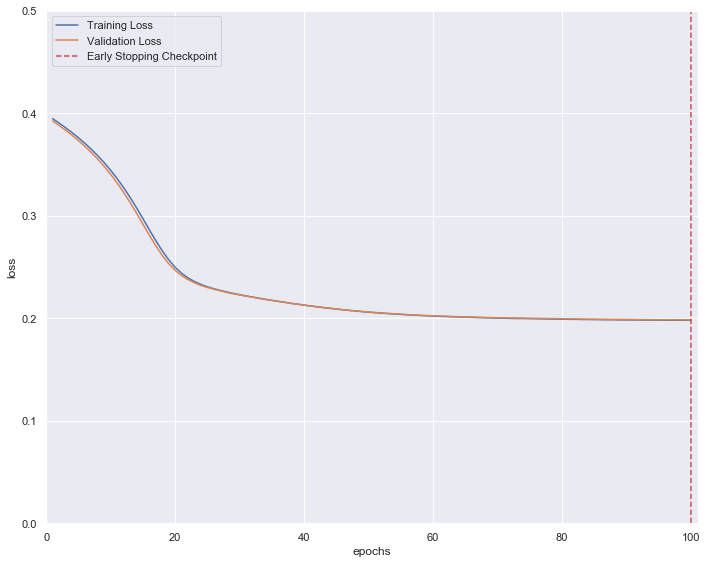
The loss doesn’t seem to be exactly identical (i.e. absolute error of zero), but the gap seems to be quite small.
How are you calculating the training and validation loss?
Usually you would record the training loss of each batch and calculate the mean afterwards. Since your model is trained during the epoch, the loss should decrease, so that the training epoch loss would have a positive bias. Your loss curves look as if you are calculating the training and validation loss after the actual training separately?
Hi ptrblck,
Thank you for answering my question. I calculate the training loss and the validation loss after training and evaluation immediately. The code is as follow.
avg_train_losses = []
avg_valid_losses = []
for epoch in range(1, EPOCH + 1):
train_losses = []
valid_losses = []
###################
# train the model #
###################
model.train() # prep model for training
for step, (x, batch_label) in enumerate(train_loader):
batch_x = x.view(-1, 1*input_layer) # batch x, shape (batch, 1*input_layer)
batch_y = x.view(-1, 1*input_layer) # batch y, shape (batch, 1*input_layer)
batch_x = Variable(batch_x).to(device)
batch_y = Variable(batch_y).to(device)
batch_label = Variable(batch_label).to(device)
### forward
encoded, decoded = model(batch_x)
loss = loss_func_decode(decoded, batch_y)
### backward
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
# perform a single optimization step (parameter update)
optimizer.step()
# record training loss
train_losses.append(loss.item())
if step % 100 == 0:
print('Epoch: ', epoch, '| train loss: %.4f' % loss.cpu().data.numpy())
######################
# validate the model #
######################
model.eval() # prep model for evaluation
for x, batch_label in val_loader:
batch_x = x.view(-1, 1*input_layer) # batch x, shape (batch, 1*input_layer)
batch_y = x.view(-1, 1*input_layer) # batch y, shape (batch, 1*input_layer)
batch_x = Variable(batch_x).to(device)
batch_y = Variable(batch_y).to(device)
batch_label = Variable(batch_label).to(device)
# forward pass: compute predicted outputs by passing inputs to the model
encoded, decoded = model(batch_x)
# calculate the loss
loss = loss_func_decode(decoded, batch_y)
# record validation loss
valid_losses.append(loss.item())
# print training/validation statistics
# calculate average loss over an epoch
train_loss = np.around(np.average(train_losses), decimals = 6)
valid_loss = np.around(np.average(valid_losses), decimals = 6)
avg_train_losses.append(train_loss)
avg_valid_losses.append(valid_loss)