I am currently training a network in pytorch and my training loss decreases but wavers a lot (it actually fluctuates in two ranges after 25 epochs of training. The training loss for roughly a third of the iterations is in the 30-40 range where as for the other two-third, it is in the 150-400 range (never in between. i.e. never between 40 and 150, only in these extreme values) as is evident from the training loss profile as follows.
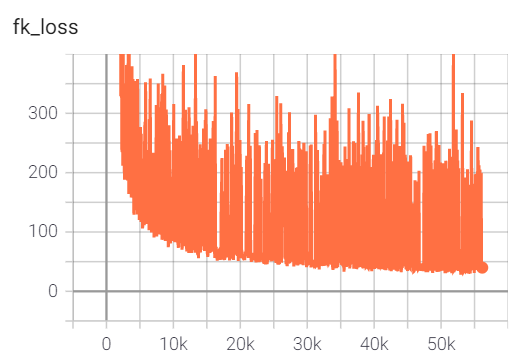
However, the validation loss has always been in the lower range (shown in the validation loss profile below).
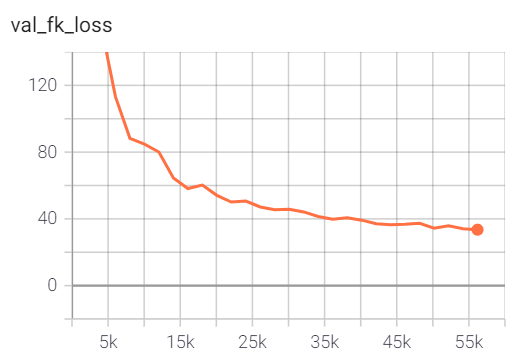
After 25 epochs, the validation loss is around 30. This makes me wonder how the validation loss is computed at the end of each epoch.
I was under the impression that whatever parameters are computed at the end of an epoch, the network is inferred for the datapoints in the validation set and the val loss is thus reported. But with that understanding, the validation loss should have been high on a few instances (when the training loss is high after the end of an epoch).
I can only think of a couple of reasons why my training loss is so unsteady.
-
The training loss curve is extremely rough full of local peaks and valleys and my learning rate is high resulting in the loss going up and down during training. However, in that case, the validation loss reported after a batch should have been unsteady as well as after the end of an epoch, the training loss can be up or low unless the network has been extremely lucky so far with low losses whenever the epoch is ending. Or unless the validation loss after each epoch is not computed based on a single set of network parameters on the validation set but instead based on 10 (let’s say) sets of network parameters and the best val loss is reported.
-
Around a third of the datapoints are poorly explained by the learnt network. Since the training loss is computed for each training datapoint separately, it is unsteady. Given that the val loss is computed on a large set of validation datapoints, the losses get averaged out and is therefore smooth. However, it does not explain why the validation loss is on the lower end of the spectrum (i.e. around 30 instead of being something like 80-100 since some of the datapoints are not fit well).
Can anyone find out some other possibility I am unable to imagine?