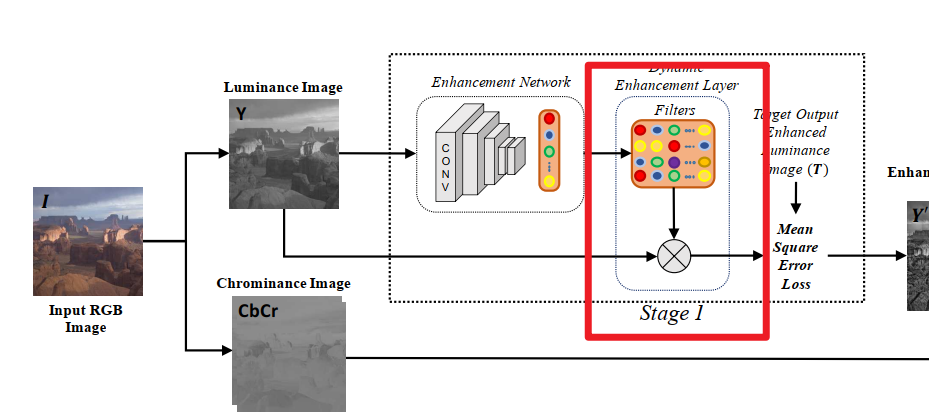
I have built an image enhancement network based on the paper , which requires convolution of the generated filter kernel and input image. However, after writing the convolution process, the model gradient will not change during training
my code is :
def extract_patche_onechannel(img, k_size, stride=1):
kernel_size = torch.zeros(k_size, k_size).cuda()
kernel_list = []
for i in range(k_size):
for j in range(k_size):
k = kernel_size.clone()
k[i][j] = 1
kernel_list.append(k)
kernel = torch.stack(kernel_list)
kernel = kernel.unsqueeze(1)
weight = nn.Parameter(data=kernel, requires_grad=True)
out = F.conv2d(img[:, :1, ...], weight, padding=int((k_size - 1) / 2), stride=stride)
return out
def forward(self, input_img):
dynamic_filters = self.general_model(input_img)
dynamic_filters = self.softmax(dynamic_filters)
input_transformed = self.extract_patche_onechannel(input_img, k_size=1)
output_dynconv = torch.sum(dynamic_filters * input_transformed.cuda(), dim=1, keepdim=True)
return output_dynconv