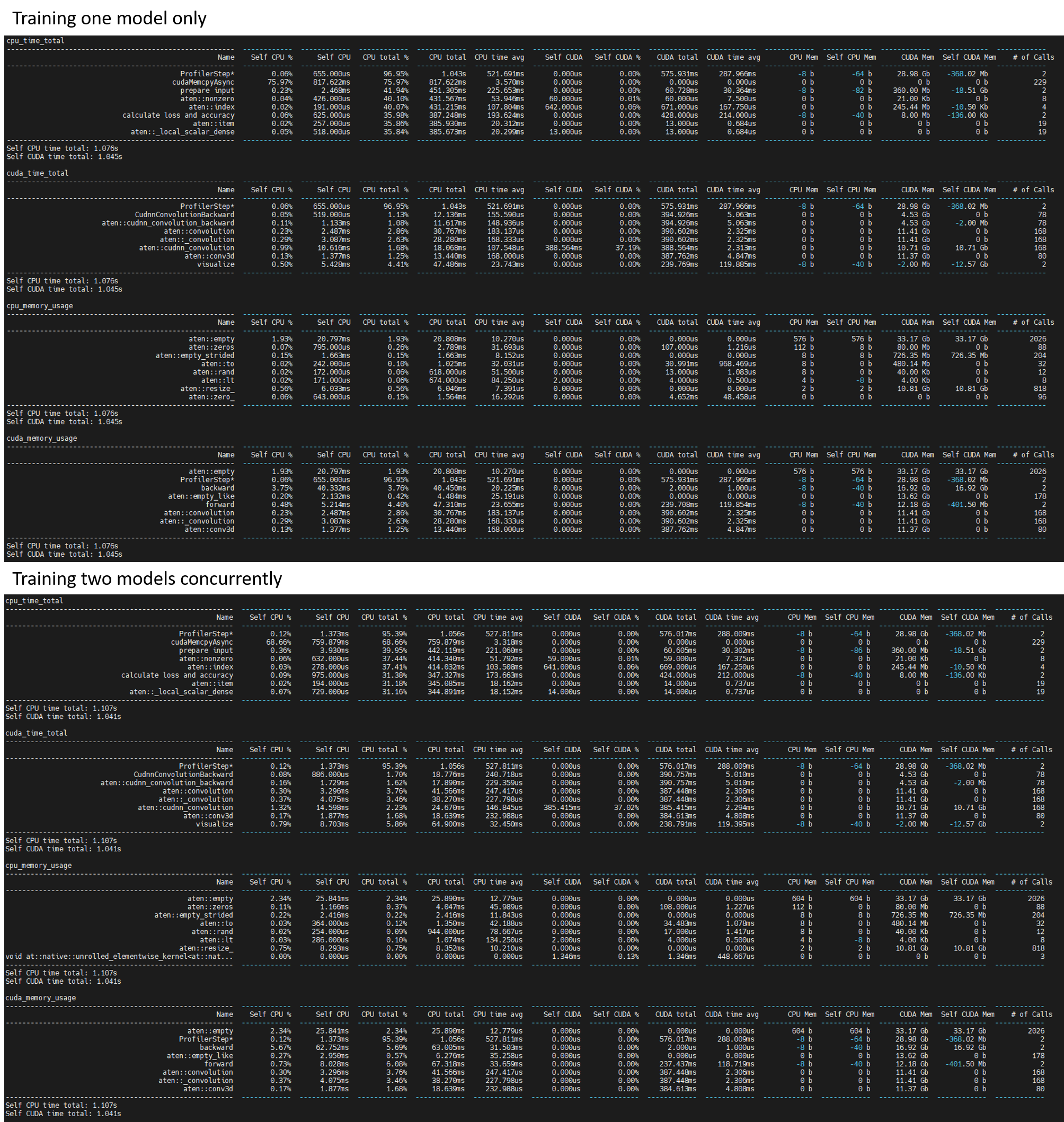
I’m currently training two variations of the following model (GitHub - TengdaHan/DPC: Video Representation Learning by Dense Predictive Coding. Tengda Han, Weidi Xie, Andrew Zisserman.).
I’ve noticed that when training both models concurrently (each on a dedicated GPU), the training time for each model increases by ~25%, as compared to when training only one model at a time.
Currently, GPU usage is >90% for both models.CPU usage is ~60% and RAM usage is ~25% when both models are trained concurrently.
Here are the profiling results (sorted by total CPU time, total CUDA time, CPU memory usage, and CUDA memory usage).