below is the code and error i am getting can anyone help me on this.
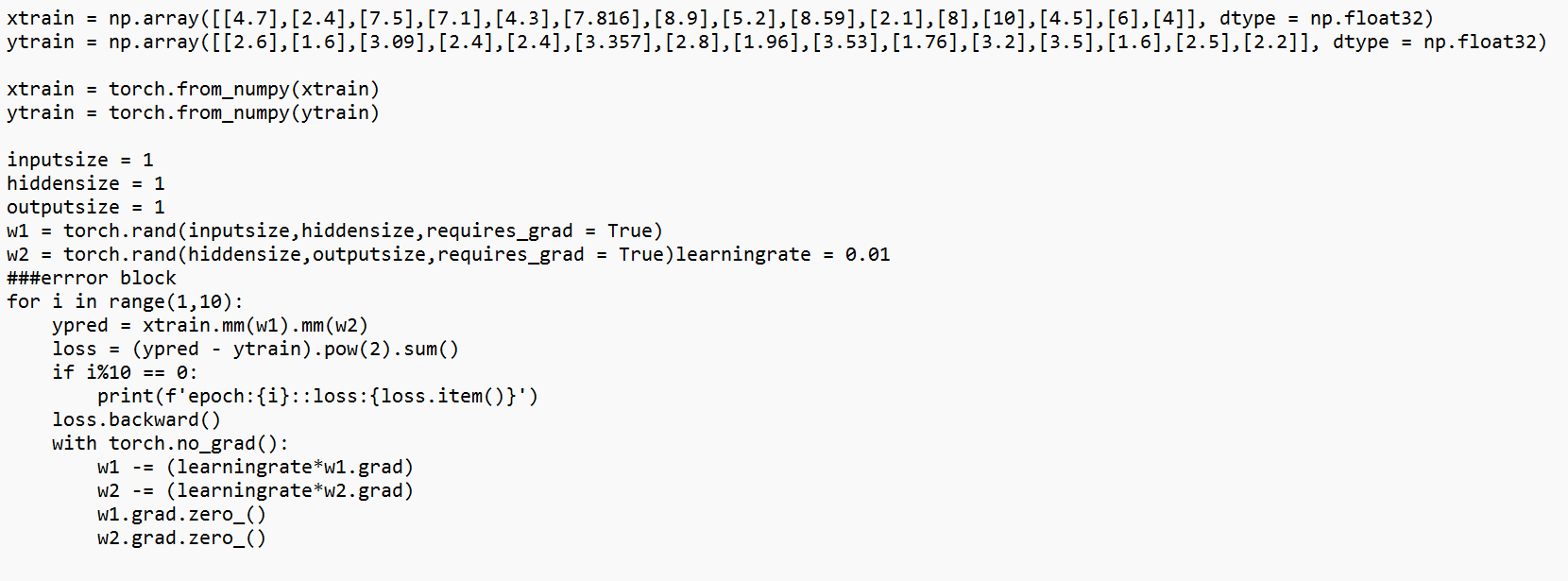
###error
RuntimeError Traceback (most recent call last)
Cell In[17], line 7
5 if i%10 == 0:
6 print(f’epoch:{i}::loss:{loss.item()}')
----> 7 loss.backward()
8 with torch.no_grad():
9 w1 -= (learningrate*w1.grad)
File /opt/conda/lib/python3.10/site-packages/torch/_tensor.py:487, in Tensor.backward(self, gradient, retain_graph, create_graph, inputs)
477 if has_torch_function_unary(self):
478 return handle_torch_function(
479 Tensor.backward,
480 (self,),
(…)
485 inputs=inputs,
486 )
→ 487 torch.autograd.backward(
488 self, gradient, retain_graph, create_graph, inputs=inputs
489 )
File /opt/conda/lib/python3.10/site-packages/torch/autograd/init.py:200, in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables, inputs)
195 retain_graph = create_graph
197 # The reason we repeat same the comment below is that
198 # some Python versions print out the first line of a multi-line function
199 # calls in the traceback and some print out the last line
→ 200 Variable.execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
201 tensors, grad_tensors, retain_graph, create_graph, inputs,
202 allow_unreachable=True, accumulate_grad=True)
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn