Hi, I would like to check how bit precision affects NN while training. I would like to check 16,32,64 bits.
So I create my model class.
class MyModel(torch.nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.l1 = torch.nn.Linear(1,32)
self.l2 = torch.nn.Linear(32,16)
self.l3 = torch.nn.Linear(16,8)
self.l4 = torch.nn.Linear(8,4)
self.l5 = torch.nn.Linear(4,1)
def forward(self, x):
x = torch.nn.functional.relu(self.l1(x))
x = torch.nn.functional.relu(self.l2(x))
x = torch.nn.functional.relu(self.l3(x))
x = torch.nn.functional.relu(self.l4(x))
x = self.l5(x)
return x
Now I create model for each precision.
model_16 = MyModel().to(dtype=torch.float16)
model_32 = MyModel().to(dtype=torch.float32)
model_64 = MyModel().to(dtype=torch.float64)
While training on 16bits exception occurs(Training code below)
%%time
err_train=[]
err_valid=[]
eposs_valid_error = [1,1]
i = 0
for epoch in range(3000):
for datum in train_loader:
optimizer_16.zero_grad()
(features,target) = datum
pred = model_16(features.to(dtype=torch.float16))
loss = loss_func(pred.to(dtype=torch.float16), target)
loss.backward()
optimizer_16.step()
with torch.no_grad():
vpred = model_16(valid_set[:][0].to(dtype=torch.float16))
vloss = loss_func(vpred,valid_set[:][1].to(dtype=torch.float16))
err_valid.append(vloss)
pred = model_16(train_set[:][0].to(dtype=torch.float16))
loss = loss_func(pred,train_set[:][1].to(dtype=torch.float16))
err_train.append(loss)
if epoch%100 == 0:
print("epoch %d %f %f " % (epoch, loss, vloss))
Exception:
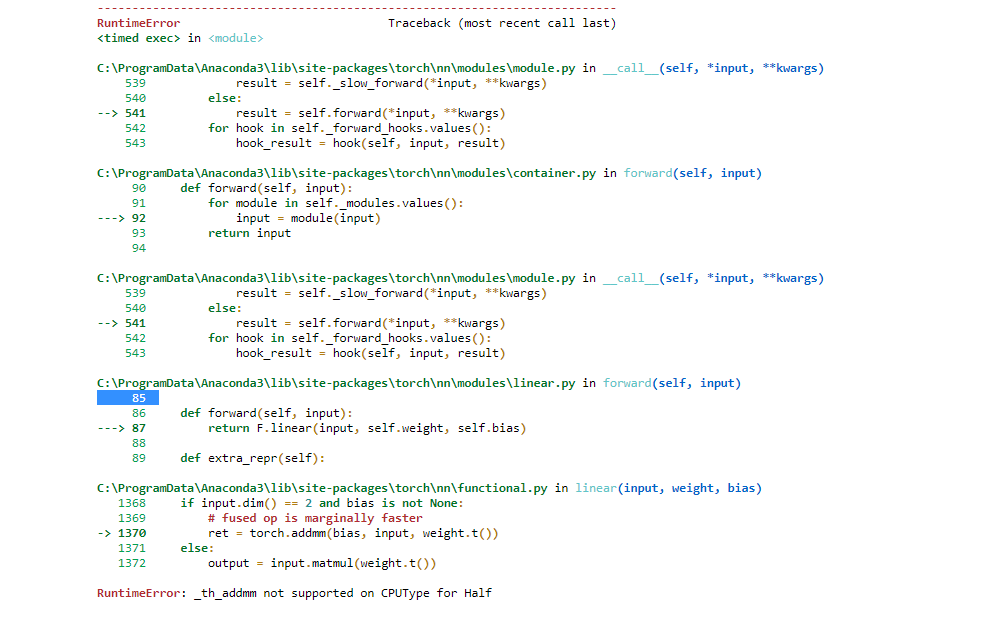
What does it mean? That I can’t train my NN on 16 floating-point precision? addmm() is the problem, so maybe I can do something around this function?