Hello,
Here we have an abstract of this problem:
Assuming that we have two models: ResNet and EfficienNet, respectively.
The first model is as follow (ResNet):
def __init__(self, in_channels, out_channels, num_classes):
super().__init__()
self.conv1_0 = _conv3x3(3, 32, stride=2)
self.bn1_0 = _bn(32)
self.conv1_1 = _conv3x3(32, 32, stride=1)
self.bn1_1 = _bn(32)
self.conv1_2 = _conv3x3(32, 64, stride=1)
self.relu = nn.ReLU()
self.pad = torch.nn.ReplicationPad2d(padding=(0, 0, 1, 1))
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2)
self.end_point = _fc(225, num_classes)
def forward(self, x):
x = self.conv1(x)
#and so on...
out = self.end_point(x)
return out
while the second model has been downloaded as follow (Efficient) :
efficientNet = models.efficientnet_b5().to(device)
So, we have two models but the first is developed to scratch and the second one is imported by torchvision.models library.
Now, we want the EfficientNet to take the output of ResNet, then make an end-to-end optimization from EfficientNet’s output to first layer of ResNet.
For mathematical reasons, assuming that we have antoher easy model between the ResNet and EfficientNet, that it’s called gumbel_model.
So, in conclusion we have 3 models but we got just one target labels about the last one of them, then we can only calculate the loss of the last model (Efficent Net).
When we calculate the loss of the last model, we actually write the three rows as follow:
optimizer.zero_grad()
loss.backforward()
optimizer.step()
Where the optimizer is as follow:
optimizer = optim.SGD(list(efficientNet.parameters()) + list(gumbel.parameters()) + list(predictor.parameters()), lr=LR)
The training method of one epoch is as follows:
efficientNet = get_efficient_trained(device, out_features=1, in_features=3,path_model)
predictor = ResNet(ResidualBlockBase, layer_config, num_classes=num_cl)
for i, imgs in enumerate(dataloader):
inputs, labels = imgs
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
predictor_output = predictor(inputs)
predictor_gumbel_output = gumbel(predictor_output)
outputs = efficientnet(predictor_gumbel_output).torch.squeeze(outputs, 1)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
return model
At testing time, the end to end model does not learn anything and I’m not sure why.
The below figure shows the loss function every 10 epochs (in total 200 epochs):
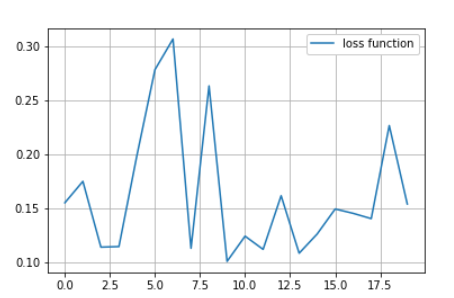
So, I thought two options:
-
The problem is that each embedding is computed on different forwards. So, it’s necessary to join the model’s objects in the forward method in a new class.
-
The weights from the each embedding must be tied during training through a layer
torch.nn.Embedding()in the_init_of models.
Could either be correct? If no, How could I solve this type of problem?
I already done hyper-parameters searching and checked that the dataloader is working fine.
Waiting for responses.
I really thank you all in advance. ![]()