I am trying to implement the relational network paper and facing the issue of training time increasing with each iteration in a haphazard manner as follows:
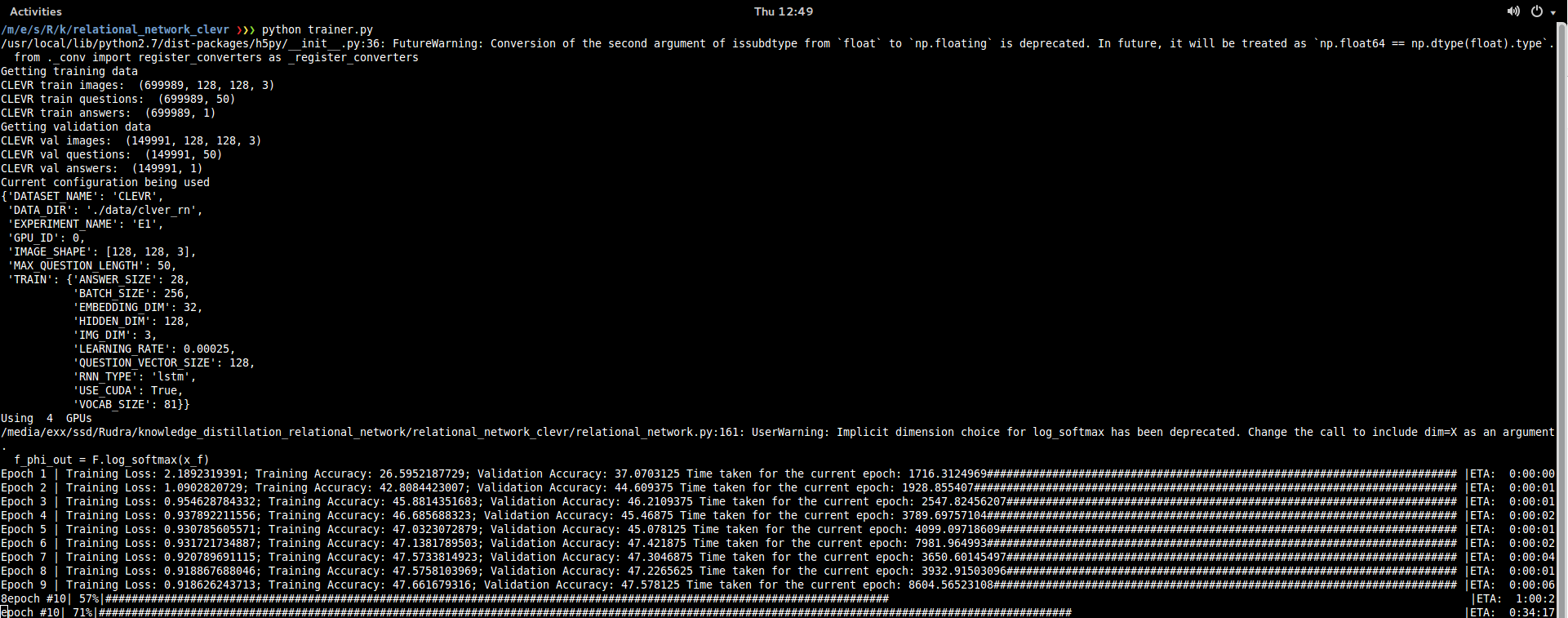
I am running this across 4 TitanX GPUs on linux 14.04. I have looked up this thread and tried to initialize the hidden state without letting them to be at default but started facing illegal memory access errors.
I have also tried launhing the code using CUDA_LAUNCH_BLOCKING=1 python trainer.py but this took what seemed like forever to start the training so I didn’t do it. I have currently stored the dataset in .h5 files and taking in the batches from it.
Please find the code of my model below:
class RelationalNetwork(nn.Module):
def __init__(self):
super(RelationalNetwork, self).__init__()
# Define the parameters for the RN network
self.conv_layer_channels = [24, 24, 24, 24] # Can be substituted by some other file
self.in_dim = cfg.TRAIN.IMG_DIM # Working only on CLEVR
self.g_theta_units = [256, 256, 256, 256] # Can be substituted as well
self.question_vector_size = cfg.TRAIN.QUESTION_VECTOR_SIZE
self.embedding_dim = cfg.TRAIN.EMBEDDING_DIM
self.vocab_size = cfg.TRAIN.VOCAB_SIZE
self.answer_size = cfg.TRAIN.ANSWER_SIZE
self.batch_size = cfg.TRAIN.BATCH_SIZE
self.use_cuda = cfg.TRAIN.USE_CUDA # Can be set using args and thus can be substituted
self.rnn_type = cfg.TRAIN.RNN_TYPE
self.n_layers = 1
# Define the word embedding for the input questions
self.question_embeddings = nn.Embedding(self.vocab_size, self.embedding_dim, padding_idx=0)
# Define the lstm to process the questions
self.lstm = nn.LSTM(self.embedding_dim, self.question_vector_size, num_layers=1)
# Initialize the hidden state of the lstm
# TODO: Check different initializations of the hidden state, currently let them default to zero
# self.hidden = self.init_hidden()
# Define the other layers of the relational network
self.convolutional_layer()
self.g_theta_layer()
self.f_phi_layer()
def init_hidden(self, x=None):
if self.rnn_type == 'lstm':
# As I am using 4 GPUs
if x == None:
return (Variable(torch.zeros(self.n_layers, self.batch_size / 4, self.question_vector_size)),
Variable(torch.zeros(self.n_layers, self.batch_size / 4, self.question_vector_size)))
else:
return (Variable(x[0].data), Variable(x[1].data)) # TODO: Problem might be here
def convolutional_layer(self):
self.conv1 = nn.Conv2d(self.in_dim, self.conv_layer_channels[0], 3, stride=2, padding=1)
self.bn1 = nn.BatchNorm2d(self.conv_layer_channels[0])
self.conv2 = nn.Conv2d(self.conv_layer_channels[0], self.conv_layer_channels[1], 3, stride=2, padding=1)
self.bn2 = nn.BatchNorm2d(self.conv_layer_channels[1])
self.conv3 = nn.Conv2d(self.conv_layer_channels[1], self.conv_layer_channels[2], 3, stride=2, padding=1)
self.bn3 = nn.BatchNorm2d(self.conv_layer_channels[2])
self.conv4 = nn.Conv2d(self.conv_layer_channels[2], self.conv_layer_channels[3], 3, stride=2, padding=1)
self.bn4 = nn.BatchNorm2d(self.conv_layer_channels[3])
def g_theta_layer(self):
self.g_fc1 = nn.Linear((self.conv_layer_channels[3] + 2) * 2 + self.question_vector_size, 256)
self.g_fc2 = nn.Linear(256, 256)
self.g_fc3 = nn.Linear(256, 256)
self.g_fc4 = nn.Linear(256, 256)
self.coord_oi = torch.FloatTensor(self.batch_size, 2)
self.coord_oj = torch.FloatTensor(self.batch_size, 2)
if self.use_cuda:
self.coord_oi = self.coord_oi.cuda()
self.coord_oj = self.coord_oj.cuda()
self.coord_oi = Variable(self.coord_oi)
self.coord_oj = Variable(self.coord_oj)
# For preparing the coord tensor, use the '1' dim as 64 because the size of the conv_feature_map
# is [BS x 24 x 8 x 8] thus forming a 64 object feature map for each image of the mini-batch.
self.coord_tensor = torch.FloatTensor(self.batch_size / 4, 64, 2)
if self.use_cuda:
self.coord_tensor = self.coord_tensor.cuda()
self.coord_tensor = Variable(self.coord_tensor)
np_coord_tensor = np.zeros((self.batch_size / 4, 64, 2))
for obj in range(64):
np_coord_tensor[:, obj, :] = np.array(self.cvt_coord(obj))
self.coord_tensor.data.copy_(torch.from_numpy(np_coord_tensor))
# Size of the coord tensor should be (64x64x2)
# Changing this based on the size of the convolution feature map
def cvt_coord(self, i):
ret_list = [(i/8-2)/2.0, (i%8-2)/2.0]
return ret_list
def f_phi_layer(self):
self.f_fc1 = nn.Linear(256, 256)
self.f_fc2 = nn.Linear(256, 256)
self.f_fc3 = nn.Linear(256, self.answer_size)
def apply_convolution(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = F.relu(self.bn4(self.conv4(x)))
return x
def apply_g_theta(self, conv_feature_map, question_vector):
x = conv_feature_map
# The code below is adopted from:
# https://github.com/kimhc6028/relational-networks
# Instead of using for loops, accessing the objects for g_theta in a vectorized manner.
mb = self.batch_size / 4
num_channels = self.conv_layer_channels[-1]
d = x.size()[2]
# Create x_flat
x_flat = x.view(mb, num_channels, d*d).permute(0, 2, 1)
# add coordinates
x_flat = torch.cat([x_flat, self.coord_tensor], 2)
# add questions everywhere
question_vector = torch.unsqueeze(question_vector, 1)
question_vector = question_vector.repeat(1, 64, 1)
question_vector = torch.unsqueeze(question_vector, 2)
# cast pairs against each other
x_i = torch.unsqueeze(x_flat, 1)
x_i = x_i.repeat(1, 64, 1, 1)
x_j = torch.unsqueeze(x_flat, 2)
x_j = torch.cat([x_j, question_vector], 3)
x_j = x_j.repeat(1, 1, 64, 1)
# concatenate everything to create x_full
x_full = torch.cat([x_i, x_j], 3)
# reshape for the network
x_ = x_full.view(mb*d*d*d*d, 26+26+128)
x_ = F.relu(self.g_fc1(x_))
x_ = F.relu(self.g_fc2(x_))
x_ = F.relu(self.g_fc3(x_))
x_ = F.relu(self.g_fc4(x_))
# reshape and sum for the f_phi network
x_g = x_.view(mb, d*d*d*d, 256)
x_g = x_g.sum(1).squeeze()
return x_g
def apply_f_phi(self, x_g):
x_f = F.relu(self.f_fc1(x_g))
x_f = F.dropout(F.relu(self.f_fc2(x_f)))
x_f = self.f_fc3(x_f)
f_phi_out = F.log_softmax(x_f)
return f_phi_out
def forward(self, image, question_vector):
question_vector = self.question_embeddings(question_vector)
question_vector = question_vector.permute(1, 0, 2)
# Pass the question vector through the lstm to get the final state vector out
self.lstm.flatten_parameters()
out_question_vector, out_hidden = self.lstm(question_vector)
self.lstm.flatten_parameters()
out_question_vector = out_question_vector[-1]
conv_feature_map = self.apply_convolution(image)
g_theta_output = self.apply_g_theta(conv_feature_map=conv_feature_map, question_vector=out_question_vector)
f_phi_out = self.apply_f_phi(g_theta_output)
return f_phi_out
This is without the re-initialization of the hidden state. I tried that but received an illegal memory access error which I think is because of the else case in the init_hidden method.
My training file is as below:
# Define the model and port it to gpu
model = RelationalNetwork()
if torch.cuda.device_count() > 1:
print("Using ", torch.cuda.device_count(), " GPUs")
model = nn.DataParallel(model)
if args.cuda:
model = model.cuda()
# Define the optimizer for training the network
optimizer = optim.Adam(model.parameters(), lr=cfg.TRAIN.LEARNING_RATE)
# criterion = nn.CrossEntropyLoss()
# Define the train step
def train(updates_per_epoch):
train_loss = 0.0
train_accuracy = 0.0
for iteration in range(updates_per_epoch):
pbar.update(iteration)
images, questions, answers = train_dataset.next_batch(args.batch_size)
# Convert the input images into tensor Variables
images = Variable(torch.from_numpy(images).permute(0, 3, 1, 2).float())
# Process the questions and answers separately
questions = Variable(torch.LongTensor(questions))
answers = Variable(torch.LongTensor(answers)).view(args.batch_size)
if args.cuda:
images = images.cuda()
questions = questions.cuda()
answers = answers.cuda()
model.zero_grad()
answers_hat = model(images, questions)
loss = F.nll_loss(answers_hat, answers)
# print("The loss is getting calculated here")
loss.backward()
optimizer.step()
train_loss += loss.data[0]
pred = answers_hat.data.max(1)[1]
correct = pred.eq(answers.data).cpu().sum()
accuracy = correct * 100. / len(answers)
train_accuracy += accuracy
train_accuracy = train_accuracy / updates_per_epoch
train_loss = train_loss / updates_per_epoch
return train_loss, train_accuracy
# Define the validation step, currently doing it for 10 random batches
def val():
model.eval()
val_accuracy = 0.0
for _ in range(10):
val_images, val_questions, val_answers = val_dataset.next_batch(args.batch_size)
# Convert the validation images into tensor Variables
val_images = Variable(torch.from_numpy(val_images).permute(0, 3, 1, 2).float())
# Process the questions and the answers
val_questions = Variable(torch.LongTensor(val_questions))
val_answers = Variable(torch.LongTensor(val_answers)).view(args.batch_size)
if args.cuda:
val_images = val_images.cuda()
val_questions = val_questions.cuda()
val_answers = val_answers.cuda()
val_answers_hat = model(val_images, val_questions)
val_pred = val_answers_hat.data.max(1)[1]
val_correct = val_pred.eq(val_answers.data).cpu().sum()
accuracy = val_correct * 100.0 / len(val_answers)
val_accuracy += accuracy
val_accuracy = val_accuracy / 10.0
return val_accuracy
# Define the parameters to be used by the progress bar
number_examples = train_dataset._num_examples # See this value and if this works.
updates_per_epoch = number_examples // cfg.TRAIN.BATCH_SIZE
# Create one-hot answers dictionary to be used in prepare answers
with open('./data/clver_rn/answer_to_ix.json', 'r') as answer_file:
answer_to_ix = json.load(answer_file)
answer_to_one_hot = {}
one_hot_init_vector = [0] * len(answer_to_ix)
# Set up the training loop
for epoch in range(1, args.epochs + 1):
epoch_start_time = time.time()
widgets = ['epoch #%d|' % epoch, Percentage(), Bar(), ETA()]
pbar = ProgressBar(maxval=updates_per_epoch, widgets=widgets)
pbar.start()
# Call the train and the test step for the dataset
epoch_loss, epoch_accuracy = train(updates_per_epoch)
log_line_train = '%s: %s; %s: %s; ' % ("Training Loss", epoch_loss, "Training Accuracy", epoch_accuracy)
val_accuracy = val()
log_line_val = '%s: %s ' % ("Validation Accuracy", val_accuracy)
epoch_end_time = time.time()
time_taken = epoch_end_time - epoch_start_time
log_time_line = '%s: %s' % ("Time taken for the current epoch", time_taken)
print("Epoch %d | " % (epoch) + log_line_train + log_line_val + log_time_line)
sys.stdout.flush()
Any advice to solve this issue is appreciated.