Dear members,
While I was doing some practices to be familiar with multi GPU training, I found out that there is a difference not only in running time but also in training speed, e.g. number of epochs taken to get the same level of loss/accuracy.
I have trained a custom, yet simple, CNN model on a custom dataset of 6-classes classification problem with a single GPU and two GPUs separately.
Everything is same except
model = nn.DataParallel(model)
in multi GPU training.
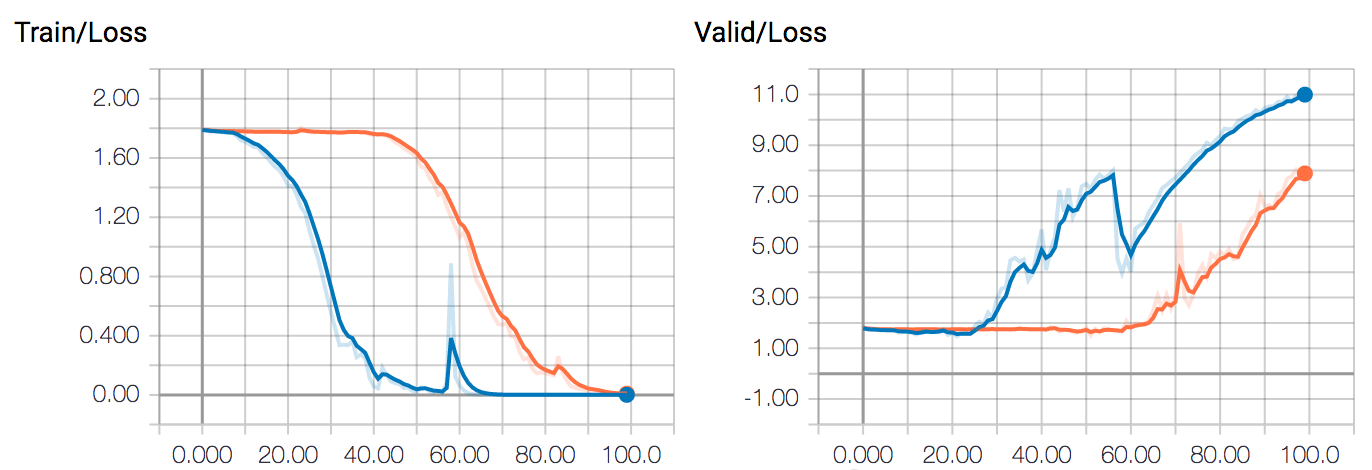
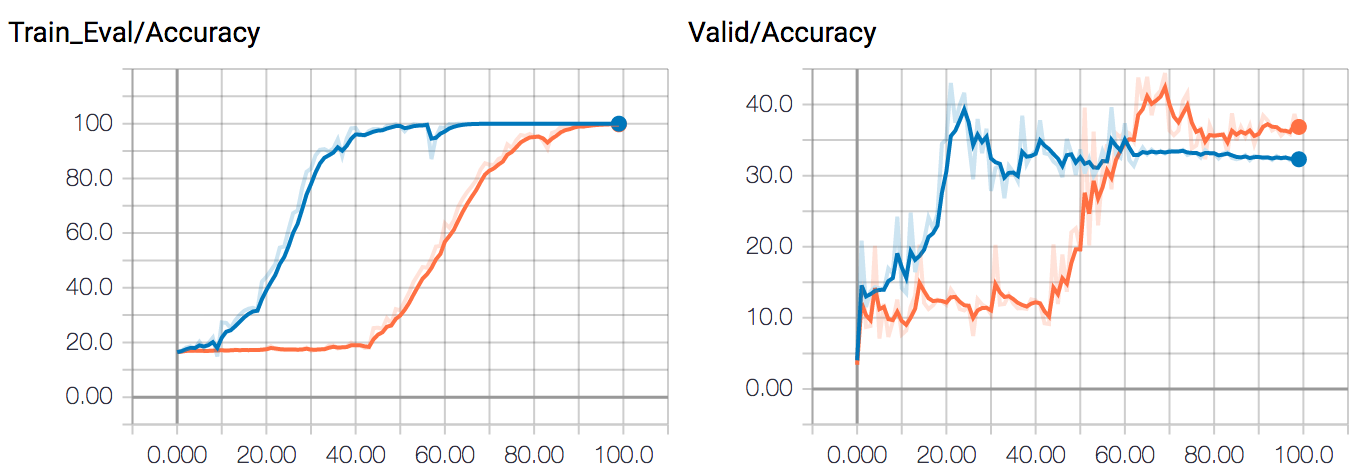
Attached figure contains loss (NLL loss after log-softmax) and accuracy plot over epochs.
ORANGE line is for single GPU and BLUE line is for multi GPU training.
I was intentionally overfitting the training set so that I can check if my draft model was being trained, so you do not need to worry about overfitting shown in the plots.
The point is that it is clear training with multiple GPUs converges quicker than with a single GPU.
I am wondering whether it is expected result since I thought that using DataParallel is just splitting batch into chunks fed into each GPU and losses from backward pass are just collected to be summed/averaged together.
Thanks!