Hello everyone, I am facing the following situation: Suppose we have the following neural networks:
class A(torch.nn.Module):
def __init__(self):
super(A, self).__init__()
self.input = nn.Linear(INPUT_A_SZ, NEURONS_NUM)
self.linear1 = nn.Linear(NEURONS_NUM, NEURONS_NUM)
self.linear2 = nn.Linear(NEURONS_NUM, NEURONS_NUM)
self.linear3 = nn.Linear(NEURONS_NUM, NEURONS_NUM)
self.linear4 = nn.Linear(NEURONS_NUM, NEURONS_NUM)
self.linear5 = nn.Linear(NEURONS_NUM, NEURONS_NUM)
self.out = nn.Linear(NEURONS_NUM, DATA_VECTOR_SIZE + 1)
def forward(self, x):
x = F.relu(self.input(x))
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = F.relu(self.linear3(x))
x = F.relu(self.linear4(x))
x = F.relu(self.linear5(x))
return F.relu(self.out(x))
class B - > similar architecture with A
class C - > similar architecture with A
etc.
In the above networks, only the input size changes. My goal is to assemble these small neural networks into a bigger one, let’s call it Big_Net, where the Big_Net has a tree structured architecture. In the forward pass of Big_Net, for each intermediate node, the input for this neural network is the output of his ancestor, concatenated with the corresponding input tensor and this procedure continues until the root of the tree is reached. The final goal, is to train each one of the small neural networks of type A, B, C, etc., through the Big_Net. The difficulty here is that the architecture of Big_Net is not static, but changes all the time based on the input and there are many instances of the same subnetwork (instances of type A, B, C) in the tree. Moreover, for all the instances of the same network within the tree, I want to implement weight sharing. My first question is how to implement the weight sharing among all instances of the same network within the tree and my second question is, since the architecture of the Big_Net changes all the time, how can a define the SGD optimizer in order to train the model. Here is an example of the architecture
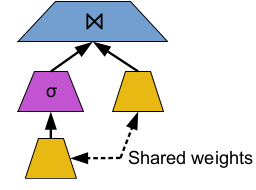
Thank you all in advance for your help!