So I was trying to move away from torchtext and create my own custom dataloader, which i think I did. I tested it out with the IMDb dataset for sentiment analysis, but I forgot to add pretrained embeddings. So I have two questions for -
1- nn.Embeddings basically creates a 2d matrix of random weights, if pretrained is not provided. And starts training them via grad descent, is this right? If so does this mean there are additional vocab_size*emb_dim parameters to train?
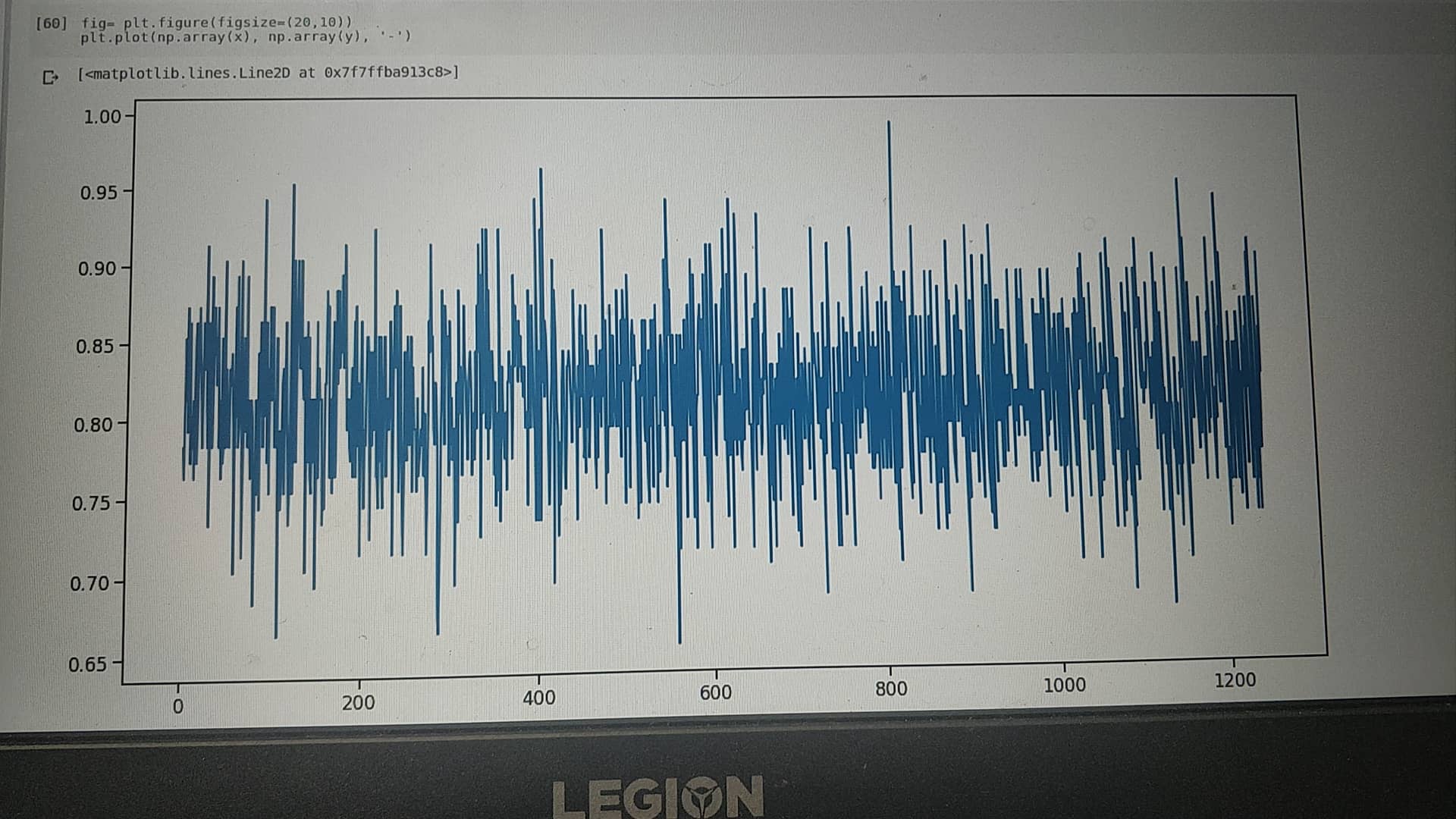
2- which brings to my follow up question, does the pretrained embeddings only function is to speed up training (by whatever factor, probably huge tho), I had the following graph of loss vs iterations without pretrained embeddings for 5 epochs. Do you think there might be any other issues in my code except embeddings?
nn.Embeddings create a 2d matrix. But, you can choose the weight initialization (eg: random or something else). Yes, if you choose to train these embeddings, there are additional vocab_size*emb_dim parameters to train.
Pre-trained embeddings not only reduce the number of parameters to train (hence reducing the train time), but also bring the “knowledge” of words (eg: word2vec) and context (eg: BERT embeddings). Hence can be directly used for downstream tasks.
Clearly, your model is not learning much (loss not decreasing with epochs). It’s hard to figure out the reason just on the basis of this plot. Better use average loss (for each epoch) to getter a better sense of loss and investigate further.
Just to add to @Abhilash_Srivastava post: Even if you used pretrained word embeddings you can decide to keep the fixed or to (further) train them. Keeping them fixed obviously increases training speed. Training them, however, might make them more adapt to our context, potentially yielding a higher accuracy.
Language is extremely multifaceted and different embedding approaches make different assumptions to map words into a vector space – that’s why we have so many embedding solutions in the first place. For example, the Skip-gram model behind Word2Vec considers to words/vectors similar, if they are used in the same context. Under this assumption, “ugly” and “beautiful” are rather close in the embedding space since words words are used to describe appearances. Thus, Word2Vec doesn’t directly capture the notion of polarity what is important for, e.g., sentiment analysis.
In short, even when using pretrained embeddings, try both: keeping them fixed vs. training them, and see what comes out of it.
Regarding your plot – although that’s pure anecdotal speculation – I don’t think that this is an embedding problem. Pretrained embeddings typically improve things but are now completely magic either. What about the first test one can do: Can you overtrain the network in a small sample of your dataset?
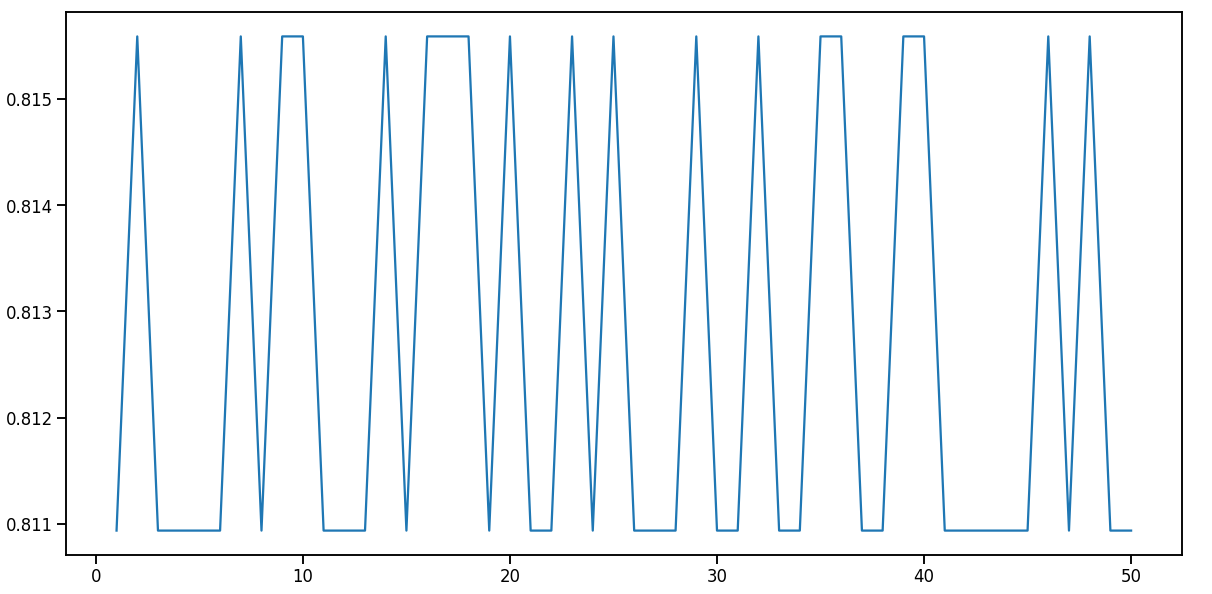
So i now i have the plot of average loss per epoch, and i have sampled 100 positive and 100 negative data points (total 200 out of 25000 texts) and ran the model for 50 epochs. this is the loss vs epoch i am getting.
I have also included the model that i wrote -
class Model(nn.Module):
def __init__(self, vocab_size, emb_dim, hid_dim, dropout = 0.5):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_dim)
self.rnn = nn.GRU(emb_dim, hid_dim)
self.fc = nn.Linear(hid_dim, 1)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
# print(src.size())
src = src.permute(1,0)
# print(src.size())
embedded = self.embedding(src)
# print(embedded.size())
output, hidden = self.rnn(embedded)
# print(output[-1].size())
out = self.fc(self.dropout(output[-1]))
# print(out.size())
return F.softmax(out, dim=1)
again all this is done without pre-trained embeddings, i will do this with pre-trained also and upload the results.
According to self.fc = nn.Linear(hid_dim, 1) you only have one output. So I assume you’re doing regression and not classification. However, use a Softmax layer in the end. Softmax is usually used for classification to “generate” a probablity distribution over all classes. While I’ve never tried it, Softmax of just one output should always be 1.0. That might explain why your network is not learning anything? Try it with out Softmax.
I removed softmax from the code, and now the code looks like -
.....
return out
instead of
return F.softmax(out, dim = 1)
I trained it for 200 epochs, without pretrained embeddings. This is the loss vs epoch plot i got.
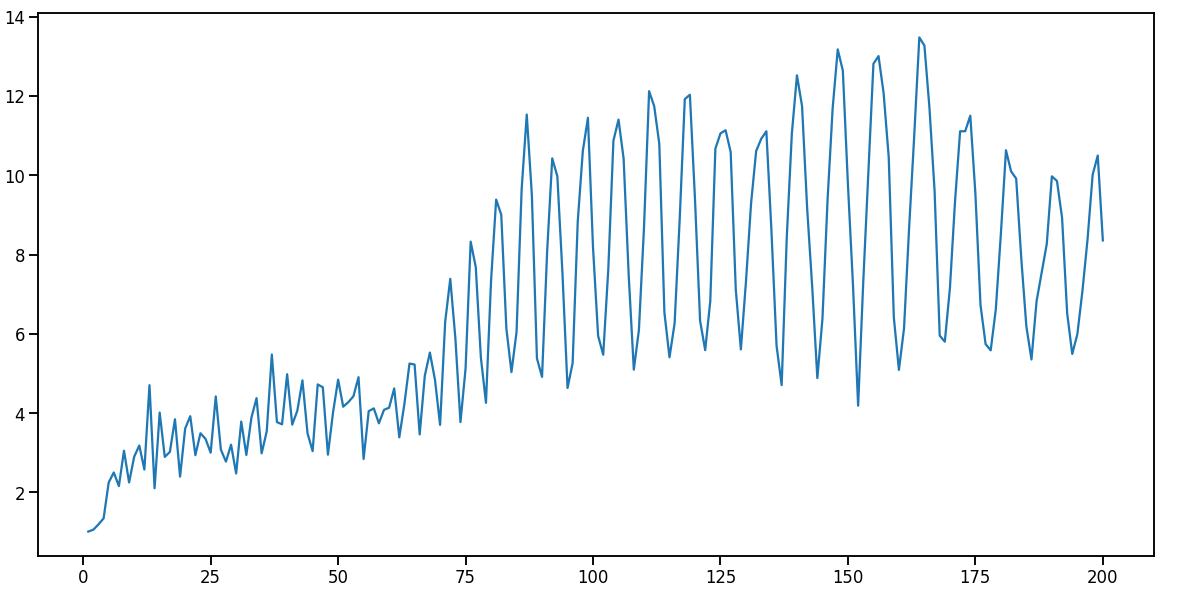
I dont understand, why is the loss increasing now? even without the the pretrained embeddings it should decrease albeit slowly.
I change my learning rate from 1e-3 to 1e-5, and trained it again for 200 epochs, I am getting a better plot now,
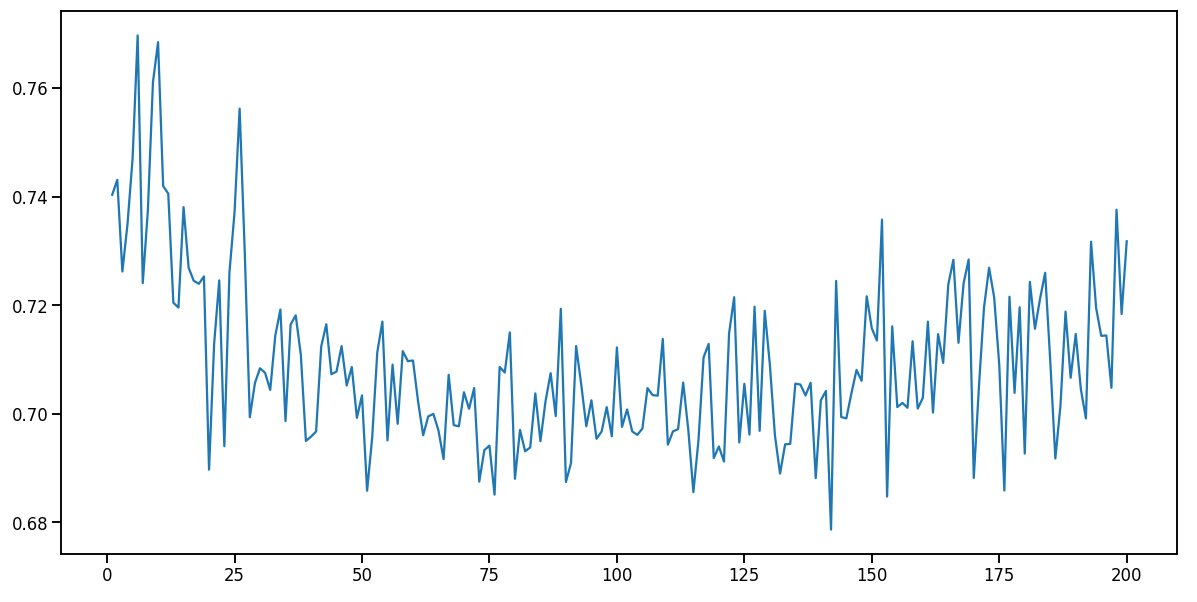
The loss is decreasing, till i guess 120-130 epochs? and then it kinda starts increasing, any possible explanation for this?
A couple of things:
- What is your loss function? For the sentiment analysis task should the sentiment fall in a range [0,1]? If yes, you should be using
nn.BCEWithLogitsLoss. - If the same dataset is used across all the epochs, the train loss value should go down (or saturate) but never increase.
Share your training code for better understanding.
I am using BCEwithlogitsloss loss function, and this is the trainer function i defined.
def trainer(train_data, epochs):
globaliter = 0
x = []
y = []
for epoch in tqdm(range(epochs)):
epoch_loss = 0
epoch_acc = 0
epoch_size = 0
for batch in tqdm(train_data):
globaliter += 1
src = Variable(batch['text']).cuda()
out = model(src)
out = out.squeeze()
trg = Variable(batch['sentiment']).cuda()
loss = criterion(out, trg)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
acc = binary_accuracy(out, trg)
epoch_acc += acc.item()
y.append(epoch_loss/len(train_data))
x.append(epoch+1)
return x,y
I will try and see what happens if i decrease my lr even more.
Did you miss using optimizer.zero_grad() before loss.backward() ?
This can also be the reason why the loss curve is not smooth.

I added return torch.sigmoid(out) inplace of return out and this is the graph i am getting. which seems a lot better.

Cool! What does your complete code look like now?
I would still want the train loss to go close to zero (over-fit for a small sample).