If I set my model.train() outside of my epoch loop (instead of inside) my model trains in train mode
only in the first epoch. After the first evaluation (which shows very low evaluation confidence while having high training confidence) the model stays in eval mode and continues training.
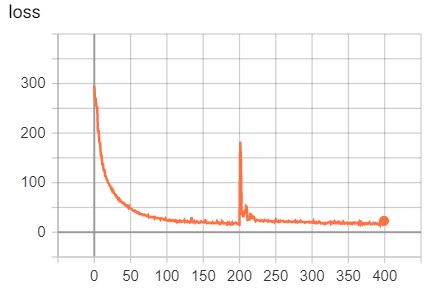
For that configuration the loss increases after evaluation shortly and than decreases again. (evaluation each 200 batches, see image)- I assume the weights leave a local minimum. After that, the training continues perfectly and I get good evaluation and detection results (Yolov3 code).
But if I set the model.train() inside the loop, the “overfitting” continues since I go back to train mode after evaluation. There is no peak in the loss function and my evaluation confidence continues to decrease (even below 0.01) even more while my training confidence converges for all three detection layers to 0.999.
I know for Dropout Layers I could just leave the Dropout Layer out or I could increase the layers. But what do I have to change for BatchNorm layers? Leaving the bn-layers completely out, leads to loss divergence.
it sounds like the expected result. I.e. the training and evaluation losses decrease properly in their corresponding mode or are you using model.train() for both, training and evaluation?
The training loss decreases in training mode while the evaluation loss increases in eval mode (which is the basic sign for overfitting).
My issue is that I do not fully understand why training works better (much better mAP performance) if I freeze my batchnorm layer after epoch 1, meaning just continue training in model.eval() instead of model.train() after one epoch.
I tried adding Dropout additional to the BN layer to prevent fast overfitting but it still shows that my training works better if I switch to model.eval() for training.
Thanks for the update.
It sounds as is the running estimates might overfit to the training data.
How large is the currently used batch size and did you change the momentum in the batchnorm layers?
If the training batch size is small (e.g. <16), the running stats might be too noisy, which would result in a bad validation performance.