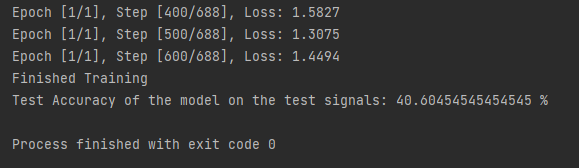
When I’m running my CNN the training looks to be working as the loss is decreasing through each Epoch but when it reaches the testing I’m getting this error to do with tensor size.
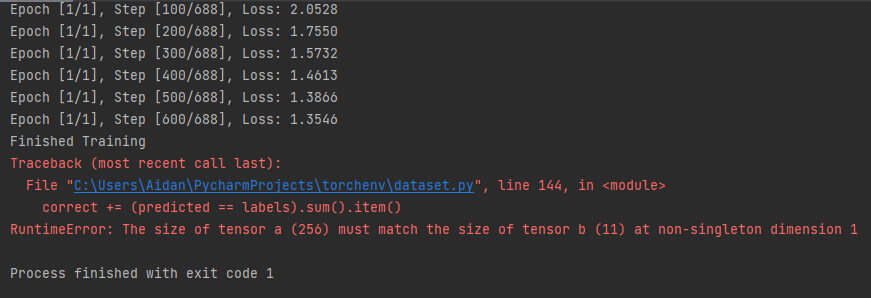
Here is my code for the CNN and training and testing. Batch size is 256, and the output I am trying to classify out of 11 different signals. Not sure why it working during training but not testing
‘’'#Input [N , 1 , 2, 128]
class ConvNet(nn.Module):
def init(self,dr=0.5,in_channels=1,num_classes=11):
super(ConvNet,self).init()
self.pad = nn.ConstantPad2d((2,2,0,0),0)
self.conv1 = nn.Conv2d(1,256,(1,3)) #First convolutional Layer (Input_channels, Output_channels, Kernel)
self.drop = nn.Dropout(dr) #Zeros some of the elements of the input tensor, probability of an element to be zeroed (p=0.5)
self.zeropad2 = nn.ConstantPad2d((2,2,0,0),0)
self.bnorm = nn.BatchNorm2d(256)
self.conv2 = nn.Conv2d(256,80,(2,3)) #Second convolutional Layer
self.bnorm2 = nn.BatchNorm2d(80)
self.Dense = nn.Linear(10560,256) # at the point will get flatten, the number of neurons required will be 10560
self.bnorm3 = nn.BatchNorm1d(256)
self.Dense2 = nn.Linear(256,num_classes)
def forward(self, x):
x = self.pad(x)
x = F.relu(self.conv1(x))
x = self.drop(x)
x = self.pad(x)
x = self.bnorm(x)
x = F.relu(self.conv2(x))
x = self.bnorm2(x)
x = torch.flatten(x,1)
x = F.relu(self.Dense(x))
x = self.bnorm3(x)
x = self.Dense2(x)
return x
conv = ConvNet().to(device)
#Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(conv.parameters(), lr=learning_rate)
#Train the Model
total_step = len(train_dl)
conv.train()
for epoch in range(num_epochs):
for i, (data, labels) in enumerate(train_dl):
# Get data to cuda if possible
data = data.reshape([data.size(dim=0), 1]+input_shape,[data.size(dim=0), 1]+input_shape)
data = data.to(device)
labels = labels.to(device)
#forward
output = conv(data)
loss = criterion(output, torch.max(labels, 1)[1])
#backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch + 1, num_epochs, i + 1, total_step, loss.item()))
print(‘Finished Training’)
Test the model
with torch.no_grad():
conv.eval()
correct = 0
total = 0
for data, labels in test_dl:
data = data.reshape([data.size(dim=0), 1]+input_shape,[data.size(dim=0), 1]+input_shape)
data = data.to(device)
labels = labels.to(device)
#forward
output = conv(data)
_, predicted = torch.max(F.softmax(output,dim=1), 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Test Accuracy of the model on the test signals: {} %'.format(100 * correct / total))