I am trying to train a pre trained model using transfer learning I am following this tutorial Building your own object detector — PyTorch vs TensorFlow and how to even get started?
I have picked FCOS: Fully Convolutional One-Stage Object Detection architecture
First step Inference
I first used inference to check which class of the pre trained model can detect my custom data(object), found class id 77 Cell Phone being detected as the custom object I want to train
Second step Train
Looking at the FCOS architecture below
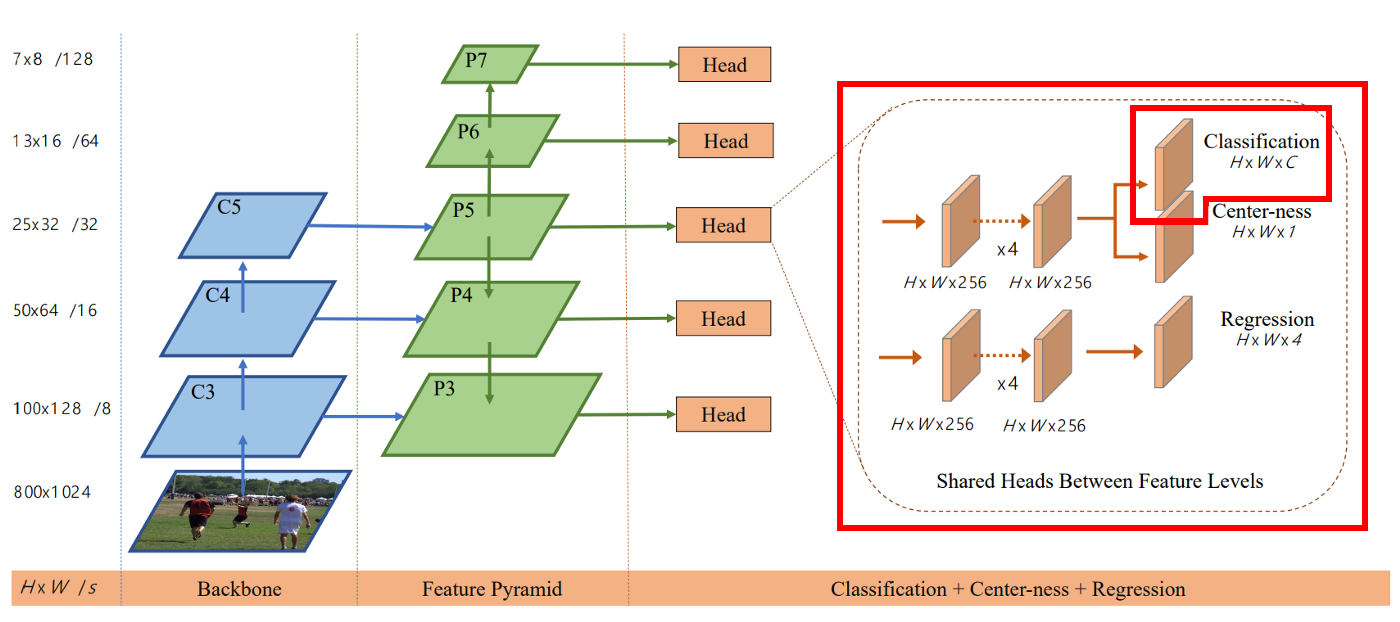
Final stage has three outputs
- Classification: Input-256 and Output-91(0:Background + 90:Classes) TO BE TRAINED
- Center-ness: Input-256 and Ouput-1
- Regression: Input-256 and Output-4(Bounding Box Coordinates)
I used requires_grad to freeze all the layers in the network and decided to train only the classification which used to predict 90 classes to train only one class
Used the code below to replace the entire classification block and pick 77th label only, replaced entire weight and bais classification with 77th class.
# load an object detection model pre-trained on COCO
model = torchvision.models.detection.fcos_resnet50_fpn(pretrained=True)
selected_head_classification_head_cls_logits_weight = 0
selected_head_classification_head_cls_logits_bias = 0
# List out all the name of the parameters whose gradient can be altered for further training
for name, param in model.named_parameters():
# If requires gradient parameters
if param.requires_grad:
if name == "head.classification_head.cls_logits.bias" or name == "head.classification_head.cls_logits.weight":
layer_para_name = "weight" if name.split('.')[-1]=='weight' else "bias"
print("\nReplacing",name,"layer containing 90 class score",layer_para_name,", with",selected_label,"th class score",layer_para_name)
print("####################################")
print("Original layer size(0:Background + 90 classes): ",param.data.size())
# Reshaping bias
if name.split('.')[-1] == 'bias':
selected_head_classification_head_cls_logits_bias = param.data[selected_label:selected_label+1]
param.data = torch.cat([param.data[:1], selected_head_classification_head_cls_logits_bias])
# Reshaping weight
if name.split('.')[-1] == 'weight':
selected_head_classification_head_cls_logits_weight = torch.tensor(param.data[selected_label][:].reshape([1, 256,3,3]))
param.data = torch.cat([param.data[:1], selected_head_classification_head_cls_logits_weight])
print("Alteres layer size(0:Background +",selected_label,"th class): ",param.data.size())
print("####################################")
print("Finished enabling requires gradient for",name,"layer......")
# Make the layer trainable
param.requires_grad = True
else:
# Make the layer non-trainable
param.requires_grad = False
OUTPUT I GOT
Replacing head.classification_head.cls_logits.weight layer containing 90 class score weight , with 77 th class score weight
####################################
Original layer size(0:Background + 90 classes): torch.Size([91, 256, 3, 3])
Alteres layer size(0:Background + 77 th class): torch.Size([2, 256, 3, 3])
####################################
Finished enabling requires gradient for head.classification_head.cls_logits.weight layer......
Replacing head.classification_head.cls_logits.bias layer containing 90 class score bias , with 77 th class score bias
####################################
Original layer size(0:Background + 90 classes): torch.Size([91])
Alteres layer size(0:Background + 77 th class): torch.Size([2])
####################################
Finished enabling requires gradient for head.classification_head.cls_logits.bias layer......
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:26: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
FCOS(
(backbone): BackboneWithFPN(
(body): IntermediateLayerGetter(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=1e-05)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=1e-05)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=1e-05)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=1e-05)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): FrozenBatchNorm2d(256, eps=1e-05)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=1e-05)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=1e-05)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=1e-05)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=1e-05)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=1e-05)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=1e-05)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=1e-05)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=1e-05)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=1e-05)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(512, eps=1e-05)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=1e-05)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=1e-05)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=1e-05)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=1e-05)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=1e-05)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=1e-05)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=1e-05)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=1e-05)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=1e-05)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=1e-05)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=1e-05)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=1e-05)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(1024, eps=1e-05)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=1e-05)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=1e-05)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=1e-05)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=1e-05)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=1e-05)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=1e-05)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=1e-05)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=1e-05)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=1e-05)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=1e-05)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=1e-05)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=1e-05)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=1e-05)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=1e-05)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=1e-05)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=1e-05)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=1e-05)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=1e-05)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(2048, eps=1e-05)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=1e-05)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=1e-05)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=1e-05)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=1e-05)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=1e-05)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=1e-05)
(relu): ReLU(inplace=True)
)
)
)
(fpn): FeaturePyramidNetwork(
(inner_blocks): ModuleList(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
)
(layer_blocks): ModuleList(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(extra_blocks): LastLevelP6P7(
(p6): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(p7): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
)
)
(anchor_generator): AnchorGenerator()
(head): FCOSHead(
(classification_head): FCOSClassificationHead(
(conv): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): GroupNorm(32, 256, eps=1e-05, affine=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): GroupNorm(32, 256, eps=1e-05, affine=True)
(5): ReLU()
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): GroupNorm(32, 256, eps=1e-05, affine=True)
(8): ReLU()
(9): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): GroupNorm(32, 256, eps=1e-05, affine=True)
(11): ReLU()
)
(cls_logits): Conv2d(256, 91, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(regression_head): FCOSRegressionHead(
(conv): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): GroupNorm(32, 256, eps=1e-05, affine=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): GroupNorm(32, 256, eps=1e-05, affine=True)
(5): ReLU()
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): GroupNorm(32, 256, eps=1e-05, affine=True)
(8): ReLU()
(9): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): GroupNorm(32, 256, eps=1e-05, affine=True)
(11): ReLU()
)
(bbox_reg): Conv2d(256, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bbox_ctrness): Conv2d(256, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(transform): GeneralizedRCNNTransform(
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
Resize(min_size=(800,), max_size=1333, mode='bilinear')
)
)
When I started training
num_epochs = 10
for epoch in range(num_epochs):
# train for one epoch, printing every 10 iterations
train_one_epoch(model, optimizer, data_loader, device, epoch,print_freq=10)
# update the learning rate
lr_scheduler.step()
# evaluate on the test dataset
evaluate(model, data_loader_test, device=device)
I get this error
/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py:490: UserWarning: This DataLoader will create 4 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
cpuset_checked))
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-17-05e881bbc3b2> in <module>()
2 for epoch in range(num_epochs):
3 # train for one epoch, printing every 10 iterations
----> 4 train_one_epoch(model, optimizer, data_loader, device, epoch,print_freq=10)
5 # update the learning rate
6 lr_scheduler.step()
6 frames
/content/drive/MyDrive/PytorchObjectDetector/engine.py in train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq)
30 print("######################",targets)
31
---> 32 loss_dict = model(images, targets)
33
34 losses = sum(loss for loss in loss_dict.values())
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1108 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1109 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1110 return forward_call(*input, **kwargs)
1111 # Do not call functions when jit is used
1112 full_backward_hooks, non_full_backward_hooks = [], []
/usr/local/lib/python3.7/dist-packages/torchvision/models/detection/fcos.py in forward(self, images, targets)
594
595 # compute the fcos heads outputs using the features
--> 596 head_outputs = self.head(features)
597
598 # create the set of anchors
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1108 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1109 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1110 return forward_call(*input, **kwargs)
1111 # Do not call functions when jit is used
1112 full_backward_hooks, non_full_backward_hooks = [], []
/usr/local/lib/python3.7/dist-packages/torchvision/models/detection/fcos.py in forward(self, x)
120
121 def forward(self, x: List[Tensor]) -> Dict[str, Tensor]:
--> 122 cls_logits = self.classification_head(x)
123 bbox_regression, bbox_ctrness = self.regression_head(x)
124 return {
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1108 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1109 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1110 return forward_call(*input, **kwargs)
1111 # Do not call functions when jit is used
1112 full_backward_hooks, non_full_backward_hooks = [], []
/usr/local/lib/python3.7/dist-packages/torchvision/models/detection/fcos.py in forward(self, x)
184 # Permute classification output from (N, A * K, H, W) to (N, HWA, K).
185 N, _, H, W = cls_logits.shape
--> 186 cls_logits = cls_logits.view(N, -1, self.num_classes, H, W)
187 cls_logits = cls_logits.permute(0, 3, 4, 1, 2)
188 cls_logits = cls_logits.reshape(N, -1, self.num_classes) # Size=(N, HWA, 4)
RuntimeError: shape '[2, -1, 91, 168, 96]' is invalid for input of size 64512
I don’t understand what is happening, How do I correct this?