I met a wired problem when running these simple lines:
import torch
cuda0 = torch.device('cuda:0')
x = torch.tensor([1., 2.], device=cuda0)
And I strace the process and find it falls into an infinite loop
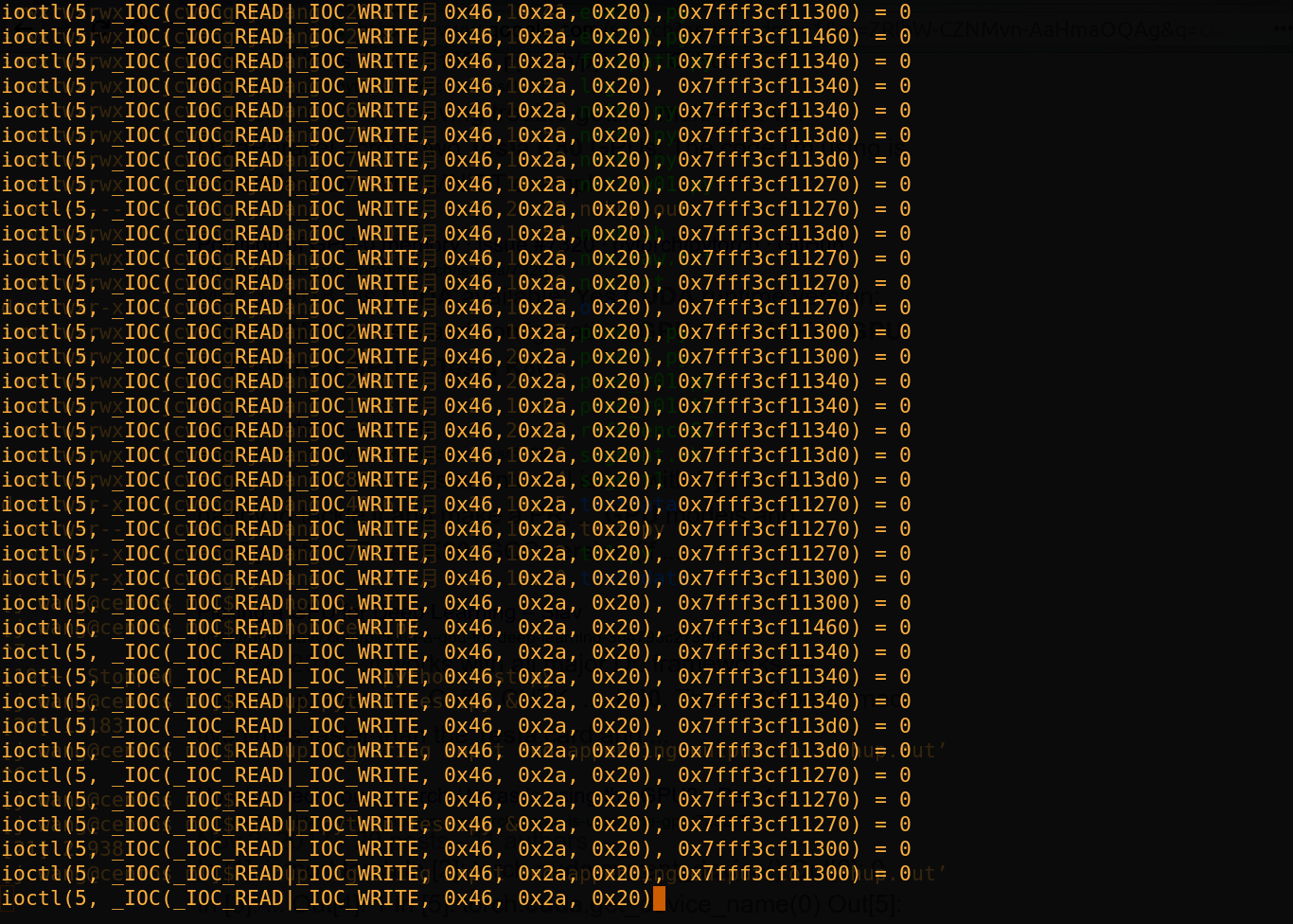
The OS is Centos 7.5, pytorch 0.40 with CUDA 9.0. There are two GPU cards on the computer and the “cuda:0” is a Tesla K40c:
02:00.0 VGA compatible controller: NVIDIA Corporation GK107GL [Quadro K420] (rev a1)
02:00.1 Audio device: NVIDIA Corporation GK107 HDMI Audio Controller (rev a1)
81:00.0 3D controller: NVIDIA Corporation GK110BGL [Tesla K40c] (rev a1)
I installed the CUDA 9.0 with rpm and samples turned out to be OK:
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 2 CUDA Capable device(s)
Device 0: "Tesla K40c"
CUDA Driver Version / Runtime Version 9.2 / 9.0
CUDA Capability Major/Minor version number: 3.5
Total amount of global memory: 11441 MBytes (11996954624 bytes)
(15) Multiprocessors, (192) CUDA Cores/MP: 2880 CUDA Cores
GPU Max Clock rate: 745 MHz (0.75 GHz)
Memory Clock rate: 3004 Mhz
Memory Bus Width: 384-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 129 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
Device 1: "Quadro K420"
CUDA Driver Version / Runtime Version 9.2 / 9.0
CUDA Capability Major/Minor version number: 3.0
Total amount of global memory: 1998 MBytes (2094989312 bytes)
( 1) Multiprocessors, (192) CUDA Cores/MP: 192 CUDA Cores
GPU Max Clock rate: 876 MHz (0.88 GHz)
Memory Clock rate: 891 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 262144 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 2 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
> Peer access from Tesla K40c (GPU0) -> Quadro K420 (GPU1) : No
> Peer access from Quadro K420 (GPU1) -> Tesla K40c (GPU0) : No
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 9.2, CUDA Runtime Version = 9.0, NumDevs = 2
Result = PASS
and bandwidth test:
Running on...
Device 0: Tesla K40c
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 10300.5
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 10240.1
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 183721.5
Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
and
In [3]: torch.cuda.is_available()
Out[3]: True
I don’t know where the problem is. Could someone help me please?