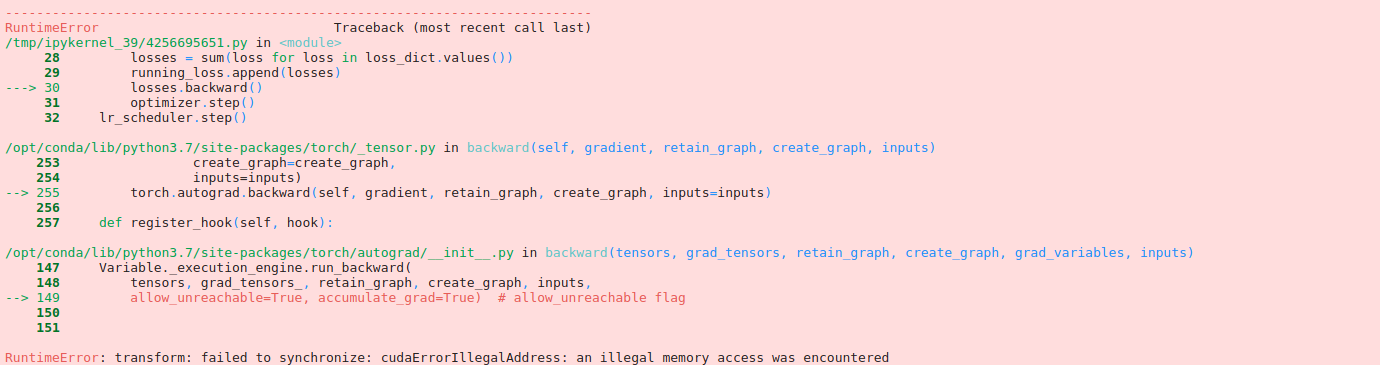
Thanks! I’ve tried to reproduce the issue using this code:
import numpy as np
import torch
import torch
from torch.utils.data import Dataset, DataLoader
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor
def decode_rle_to_mask(rle_array, height, width, viz=False):
mask = np.zeros((height*width, 1))
if viz:
color = np.random.rand(3)
else:
color = [1]
for i in rle_array:
mask[int(i[0]):int(i[0])+int(i[1]), :] = color
result = mask.reshape(height, width)
return result
def create_mask(df, image_id, height, width):
filtered_df = df[df.id == image_id]
result_array = np.zeros(height * width).reshape(height, width)
for index, row in filtered_df.iterrows():
annotation_list = row["annotation"].split()
annotation_list = map(int, annotation_list)
annotation_list = list(annotation_list)
annotation_np_array = np.array(annotation_list)
annotation_np_array = annotation_np_array.reshape(-1, 2)
annotation_np_array[:,0] -= 1
result_array = result_array + decode_rle_to_mask(annotation_np_array, height, width)
result_array[result_array > 1] = 1
return result_array
def mask_on_image(path_to_image, image_name, height, width, df):
original_array = cv2.imread(os.path.join(path_to_image, image_name + '.png'))
result_array = create_mask(df, image_name, 520, 704)
plt.figure(figsize=(32,18))
plt.imshow(original_array, interpolation = 'none')
plt.imshow(result_array, interpolation='none', alpha = 0.2)
plt.show()
def rle2bbox(rle, shape):
'''
rle: run-length encoded image mask, as string
shape: (height, width) of image on which RLE was produced
Returns (x0, y0, x1, y1) tuple describing the bounding box of the rle mask
Note on image vs np.array dimensions:
np.array implies the `[y, x]` indexing order in terms of image dimensions,
so the variable on `shape[0]` is `y`, and the variable on the `shape[1]` is `x`,
hence the result would be correct (x0,y0,x1,y1) in terms of image dimensions
for RLE-encoded indices of np.array (which are produced by widely used kernels
and are used in most kaggle competitions datasets)
'''
a = np.fromiter(rle.split(), dtype=np.uint)
a = a.reshape((-1, 2)) # an array of (start, length) pairs
a[:,0] -= 1 # `start` is 1-indexed
x0 = a[:,0] % shape[1]
x1 = x0 + a[:,1]
if np.any(x1 > shape[1]):
# got `y` overrun, meaning that there are a pixels in mask on 0 and shape[0] position
x0 = 0
x1 = shape[1]
else:
x0 = np.min(x0)
x1 = np.max(x1)
y0 = a[:,0] // shape[1]
y1 = (a[:,0] + a[:,1]) // shape[1]
y0 = np.min(y0)
y1 = np.max(y1)
if x1 > shape[1]:
# just went out of the image dimensions
raise ValueError("invalid RLE or image dimensions: x1=%d > shape[1]=%d" % (
x1, shape[1]
))
return x0, y0, x1, y1
def create_bbox_list_by_image(df, image_id):
filtered_df = df[df.id == image_id]
return_list = []
for index, row in filtered_df.iterrows():
annotation_list = row["annotation"]
height, width = row["height"], row["width"]
return_list.append(rle2bbox(annotation_list, (height, width)))
return return_list
def update_dataset_with_bbox(df):
df["bbox"] = "empty"
for index, row in df.iterrows():
sample_annot = row["annotation"]
height, width = row["height"], row["width"]
x0, y0, x1, y1 = rle2bbox(sample_annot, (height, width))
df["bbox"][index] = f"{x0} {y0} {x1} {y1}"
return df
def my_collate(batch):
return tuple(zip(*batch))
num_classes = 2
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained = True)
for param in model.parameters():
param.requires_grad = False
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask, hidden_layer, num_classes)
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model = model.to(device)
class MyDataset(Dataset):
def __init__(self):
self.length = 100
def __len__(self):
return self.length
def __getitem__(self, idx):
image = torch.randn(3, 520, 704)
bbox = torch.zeros(1, 4).long()
bbox[0, 0] = torch.randint(0, 256, (1,))
bbox[0, 2] = bbox[0, 0] + torch.randint(1, 256, (1,))
bbox[0, 1] = torch.randint(0, 256, (1,))
bbox[0, 3] = bbox[0, 1] + torch.randint(1, 256, (1,))
mask = torch.randint(0, 2, (1, 520, 704)).float()
return image, bbox, mask
batch_size = 1
num_epochs = 10
train = MyDataset()
trainloader = torch.utils.data.DataLoader(train, batch_size=batch_size,
shuffle=True, num_workers=0, collate_fn = my_collate)
for param in model.rpn.parameters():
param.requires_grad = True
optimizer = torch.optim.AdamW(filter(lambda p: p.requires_grad, model.parameters()), lr=0.01, betas=(0.9, 0.999), eps=1e-08, weight_decay=0.01, amsgrad=False)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 500, gamma=0.01, last_epoch=- 1, verbose=False)
for epoch in range(num_epochs):
running_loss = []
loss_classifier = []
loss_box_reg = []
loss_mask = []
loss_objectness = []
loss_rpn_box_reg = []
for images, bbox_targets, mask_targets in trainloader:
images = list(image.to(device) for image in images)
bbox_targets = list(bbox_target.to(device) for bbox_target in bbox_targets)
mask_targets = list(mask_target.to(device) for mask_target in mask_targets)
targets = list({} for image in images)
for i,target in enumerate(targets):
target["boxes"] = bbox_targets[i]
target["masks"] = mask_targets[i]
target["labels"] = torch.ones(bbox_targets[i].shape[0], dtype=torch.int64).to(device)
optimizer.zero_grad()
loss_dict = model(images, targets)
loss_classifier.append(loss_dict['loss_classifier'])
loss_box_reg.append(loss_dict['loss_box_reg'])
loss_mask.append(loss_dict['loss_mask'])
loss_objectness.append(loss_dict['loss_objectness'])
loss_rpn_box_reg.append(loss_dict['loss_rpn_box_reg'])
losses = sum(loss for loss in loss_dict.values())
running_loss.append(losses)
losses.backward()
optimizer.step()
lr_scheduler.step()
if (epoch + 1) % 1 == 0:
print(f"Epoch {epoch + 1}, loss: {sum(running_loss)/len(running_loss)}")
print(f"Loss classifier: {sum(loss_classifier)/len(loss_classifier)}")
print(f"Loss box regression: {sum(loss_box_reg)/len(loss_box_reg)}")
print(f"Loss mask: {sum(loss_mask)/len(loss_mask)}")
print(f"Loss objectness: {sum(loss_objectness)/len(loss_objectness)}")
print(f"Loss rpn box regression: {sum(loss_rpn_box_reg)/len(loss_rpn_box_reg)}")
but it works fine in the current stable release as well as the nightly binary.
Could you check, if this code would fail in your setup?